After presenting the highly anticipated "Capsule Networks", Geoffrey Hinton, a professor of computer science at the University of Toronto, has done some cutting-edge work on the idea of ​​distillation, including Distill the Knowledge in a Neural Network. Wait. Today we introduce Hinton as one of the authors, further work on the distillation of submissions by researchers from Google Brain, DeepMind et al.: Large-scale distributed neural network training through online distillation. This work proposes the concept of Codistillation. Through large-scale experiments, it has been found that the codistillation method improves accuracy and speeds up training, and is easy to use in practice.
In conjunction with almost any basic model, technologies such as ensembling and distillation can improve the quality of the model. However, due to the increased test-time costs (for ensembling) and the complexity of the training pipeline (for distillation), these techniques are challenging to use in an industrial environment.
Researchers from Google, Google Brain, and DeepMind, including Geoffrey Hinton and others, in their paper “Large scale distributed neural network training through online distillation†submitted to ICLR 2018, discuss a relatively straightforward variant of distillation. The method does not require complicated multilevel settings or very many new hyperparameters.

The first claim made by the researchers was that online distillation allowed us to use additional parallelism to accommodate very large data sets and double the speed. More importantly, even if we have reached the point where additional parallelism does not benefit synchronous or asynchronous random gradient descent, we can still speed up training. Two neural networks trained on disjoint data subsets can share knowledge by encouraging each model to agree with the prediction of another model. These predictions may come from older versions of another model, so they can be safely calculated using the rarely transmitted weights.
The second claim put forward by the paper is that online distillation is a cost-effective method that can make the accurate prediction of the model more repeatable. The researchers supported these claims by experimenting on the Criteo Display Ad Challenge dataset, ImageNet, and the largest data set for neurolinguistic modeling (containing 6x1011 tokens).
Codistillation: Better than Distributed SGD
For large-scale, commercially valuable neural network training problems, if the training time can be greatly accelerated, or the quality of the final model can be greatly improved, practitioners will be willing to invest more machines for training. Currently, distributed stochastic gradient descent (SGD), including its synchronous and asynchronous forms (Chen et al., 2016), is the main algorithm for large-scale neural network training on multiple interconnected machines. However, as the number of machines increases, the time required to train a high-quality model will be reduced until it is impossible to further shorten the training time by continuing to increase the machine. Infrastructure constraints and optimization barriers together limit the scalability of distributed minibatch SGD.
The exact scalability limit of distributed SGD will depend on the implementation details of the algorithm, the specific conditions of the infrastructure, and the capabilities of the hardware. However, according to our experience, effective scaling on more than 100 GPU workers may be very difficult. No algorithm for training neural networks can be infinitely extended, but it is very valuable even if it is extended a little more than the limit of distributed SGD.
Once we have reached the limit of adding workers to distributed SGD, we can use additional machines to train another copy of the model and create an ensemble to improve accuracy (or by training ensemble in fewer steps. To improve the accuracy of training. Ensemble can make more stable and repeatable predictions, which are useful in practical applications. However, ensemble increases the cost of testing and may affect delays or other cost constraints.
In order to obtain almost the same benefits as ensemble without increasing the cost of the test time, we can distill the ensemble of an n-way model to get a single model. This involves two phases: first we use the nM machine To train the n-way ensemble of the distributed SGD, then use the M machine to train the student network to simulate the n-way ensemble. By adding another phase to the training process and using more machines, distill generally increases training time and complexity in exchange for quality improvements that are closer to the teacher ensemble model.
We believe that in terms of both time and pipeline complexity, the extra training cost prevents practitioners from using ensemble distillation, although this method can always improve results. In this new work, we describe an online variant of simple distillation, which we call codistillation. Codistillation can train a copy of n models in parallel by adding an item to the loss function of the i-th model to match the average predicted values ​​of other models.
Through large-scale experiments, we found that by allowing more efficient use of more computing resources, codistillation improves accuracy and speeds up training, and even accelerates the effect of adding more workers to the SGD method. Specifically, codistillation provides the benefit of distilling a model ensemble without increasing training time. Compared to Multi-phase's distillation training process, Codistillation is also quite simple to use in practice.
The main contribution of this work is the large-scale experimental verification of codistillation. Another contribution was that we explored different design choices and codistillation implementation considerations, and put forward practical suggestions.
In general, we believe that in practice, codistillation is less important than the quality of refined distillation of offline distillation. It is more interesting to study codistillation as a distributed training algorithm.
In this paper, we use codistillation to refer to the execution of the distillation:
All models use the same architecture;
Use the same data set to train all models;
Use the distillation loss during training before any model is completely converged.

Codistillation algorithm
Experiments and results
In order to study the scalability of distributed training, we need a task that represents an important large-scale neural network training problem. Neuro-linguistic modeling is an ideal test platform because there is a large amount of text on the network, and because the training cost of the neural language model may be very high. Neurolinguistic models are representative of the important issues commonly used to implement distributed SGD (such as machine translation and speech recognition), but language modeling makes it easier to evaluate and use simpler pipelines. In order to increase the potential scalability as clearly as possible, we chose a large enough data set, which is completely impossible to train an expression model through the existing SGD parallelization strategy. To confirm that our results are not specific to certain features of language modeling, we also verified some of the large-scale codistillation results we have at ImageNet (Russakovsky et al., 2015). To demonstrate the benefits of coding in a reduced prediction process and to study other features of the algorithm, we can use smaller, cheaper experiments, but it is important to truly reach the limits of distributed SGD when studying scalability.
1. Achieve the limit of distributed SGD for training RNN on Common Crawl
In our first set of experiments, our goal was to roughly determine the maximum number of GPUs that can effectively use SGD in our Common Crawl neural language model setup. Since our dataset is two orders of magnitude larger than English Wikipedia, there is no need to worry about revisiting the data, even in relatively large-scale experiments, which will make the independent copies more similar. We try to use asynchronous SGD of 32 and 128 workers, and if necessary, assign weights by increasing the number of parameter servers to ensure that the training speed is calculated by the GPU as a time bottleneck. We find it difficult to maintain the stability of the training and prevent the difference between the RNGs and the asynchronous SGD of a large number of GPUs. We tried some worker promotion plans and different learning rates, but ultimately decided to focus on the synchronization algorithm so that our results were less dependent on our infrastructure and the specific characteristics of the implementation. Gradient stability is difficult to analyze independently of the specific conditions, and the difference between implementation and infrastructure is more easily abstracted as synchronous SGD. Although more efforts may be needed to make async work better, the debilitating effect of stale gradients on learning progress is a well-known problem. Mitliagkas et al. (2016) believe that asynchronous can effectively increase momentum, which is why it is easy to differentiate the reason. In preliminary experiments, the gains from codistillation seem to have nothing to do with choosing asynchronous or synchronous SGD as the basic algorithm.
The maximum number of GPUs that can be used simultaneously to synchronize SGD depends on the infrastructure limitations, tail delay, and batch size. Fully synchronized SGD is equivalent to a much larger batch of stand-alone algorithms. Increasing the effective batch size reduces the noise in the gradient estimate, allowing for larger step sizes, and promises higher quality updates, resulting in faster convergence speeds. Given effective unlimited training data (even if we use 256 GPUs, we don't have access to all common crawl training data), we intuitively expect to increase the effective batch size and eventually increase the step time. We trained the language model on Common Crawl using fully synchronized SGD and used batch sizes of 128 and 32, 64, 128, and 256 GPUs. Therefore, the effective batch size range is 4096 to 32768. In general, we should expect to increase the learning rate because we have increased the effective batch size, so for each GPU we are trying to learn 0.1, 0.2, and 0.4. For 32 and 64 GPUs, 0.1 performs best, because the original three learning rates did not perform well for 256 GPUs, and we also tried an additional 0.3 intermediate learning rate, which is the best performance learning rate of 256.
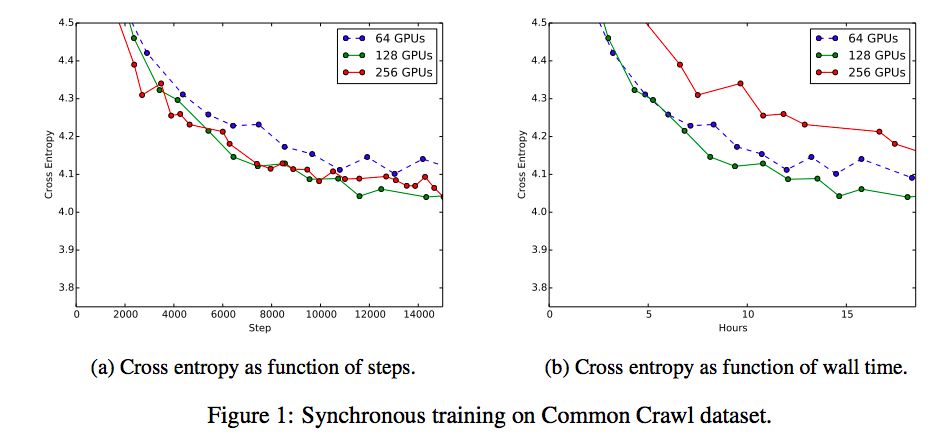
Figure 1a uses the verification error as a function of the global steps of the different number of GPUs we have tried, using the optimal learning rate for each number of GPUs. Increasing the number (and thus the effective batch size) reduces the number of steps required to achieve the best validation error, up to 128 GPU, without additional improvements at this point. Figure 1b compares the verification error of the same number of synchronous GPUs against the Wall time. In these special experiments, SGD synchronized with 128 GPUs is the strongest baseline in training time and final accuracy. Therefore, we compared the remaining experiments with 128-bit synchronous SGD and studied the use of synchronous SGD as a subprogram for codistillation, but it also applies to asynchronous algorithms.
2. CODISTILLATION with Synchronous SGD
For language modeling on Common Crawl, synchronous SGD with 128 GPUs achieves the best results of standard distributed training, at least the configuration we have tried, and we cannot use 256 GPUs to increase training time. Although the additional GPUs do not seem to help the basic synchronization of SGD, our hypothesis is that if we use two sets of 128 GPUs (using synchronous SGD to periodically exchange checkpoints) for bidirectional codistillation, then the extra 128 GPUs will increase the training time.
One problem is that codistillation is just a way to punish the output distribution (penalizing output distributions) or smoothing labels, so we also compare it with two label smoothing baselines. The first baseline replaces the codistillation loss term with a term that conforms to a uniform allocation, and the second baseline uses and uses a term that matches the unigram distribution. Manually adjust trade-off hyperparameters in preliminary experiments. Another important comparison is the integration of two neural networks, each with 128 GPUs and synchronous SGD.
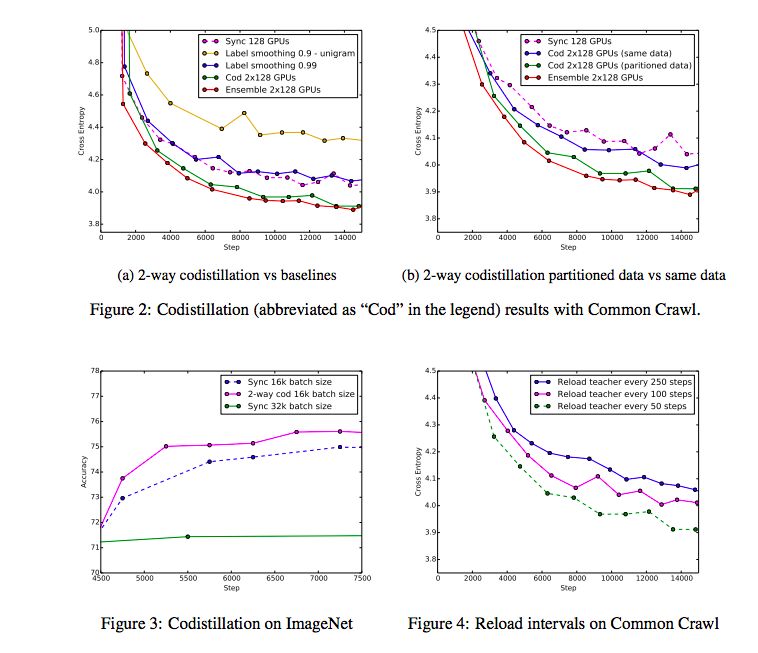
Figure 2a uses the two groups of 128 GPUs, as well as the training curve for the synchronized SGD and the label smoothing baseline (each using 128 GPUs) and a training curve containing two instances of 128 GPU baselines to plot the validation cross- information and Synchronized training steps.
Discussion and future work
Distillation is a very flexible tool, especially during and after the model training process. It can be used to accelerate training, improve quality, train with new, more effective communication methods, and reduce the loss of predictions. However, we still have many problems that need to be explored. For example, we mainly focus on model pairs that are codistilled with each other. If pairing is useful, other topologies are also useful. Fully connected graphics may make the models too similar, too fast for the ring structure to become interesting. We also did not explore the limitations of the accuracy of teacher models. It may be possible to quantify the teacher models so that they are as inexpensive as normal training, even if it is a very large model.
Somewhat paradoxically, codistilling between bad models can learn faster than independent model training. To some extent, mistakes made by teacher models can help the student model do better, and it's better than just seeing the actual tags in the data. Describe the ideal characteristics of teacher models is an exciting way to work in the future. In this work, we only extract predictions from the checkpoints, because the predictions are identifiable, and unlike the internal structure of the network, there is no false symmetry. In other words, extracting more information from one checkpoint may be more predictive than merely predicting the same problem that does not touch the staff exchange gradient, allowing the use of teacher models as stronger adjusters. It may be possible to use codistillation-based methods to enhance the joint learning proposed by McMahan et al. (2017) in a bandwidth-limited setting environment.
Fractional horsepower centrifugal switches
Fractional Horsepower Motor,Fractional Horsepower Ac Motor,3 Phase Starter Switch,Auto Motor Starter Switch
Ningbo Zhenhai Rongda Electrical Appliance Co., Ltd. , https://www.centrifugalswitch.com