The CAN bus started around 1986 and is still widely used today. Nowadays people's requirements for safety have been greatly improved, so we must constantly review the safety performance of CAN. The important CAN problems that have been discovered so far are: the equivalent offline may occur in the negative error state, so that the node can not send and receive the time is quite long [1]; the error rate of the missed frame is not accurate, especially when the bit error rate is high. It is several orders of magnitude higher than Bosch CAN2.0 data [2], affecting data correctness when single-destination address, affecting data consistency at multiple destination addresses; standard oscillation source accuracy requirements are low [3], making mistakes It is possible to use inexpensive devices, which affects the stability of the system; the possibility of priority inversion found in this paper makes the reliability of the scheduling analysis result decrease; the local error in the penultimate bit of the data frame may cause inconsistent reception repetition or loss. [4]. So before FlexRay has yet to meet its intended goals, whether it can replace CAN in terms of reliability or price, further improvements to CAN are still very meaningful.
CAN is a representative event-triggered communication protocol, and multiple communication requests occurring at the same time will perform non-destructive arbitration according to the priority of the message, and a high priority wins. Non-destructive arbitration in accordance with the priority of the message is the only claim of the original CAN patent [5]. For low priority messages, the delivery time will be blocked by high priority messages. When the high priority messages are periodic, the worst delivery time can be pre-computed [6]. If the initial phase of the message can be scheduled and the clock synchronization is relaxed, this worst-case delivery time can be greatly reduced. The advantage of the event triggering protocol is that the bus bandwidth can be fully utilized. Another advantage is that high priority messages can be sent quickly. However, due to the electromagnetic interference prevailing in the industrial environment, there will be burrs on the bus, and the countermeasures have been taken into consideration in the CAN bus standard. It is now found that the glitch coping method may affect the synchronization of the node, thereby damaging the transmission opportunity of the high priority message, and the priority inversion is reversed, which shakes the basic performance of the CAN bus.
1 burr presence
The electromagnetic environment in the car is harsh, and ISO 76372/3 summarizes the representative conduction and radiation interference. Some people have specially made experiments on radiation interference. In the experiment of reference [7], the 24 V battery is used to supply the relays commonly used in the car (the CAN system is powered independently), and the power cable is close to the CAN cable. When there is shielding and the line length is 2 m, the burrs superimposed on the CAN waveform can be seen when the relay is manually switched. The experimental results of the radiation interference are shown in Fig. 1.
This article refers to the address: http://
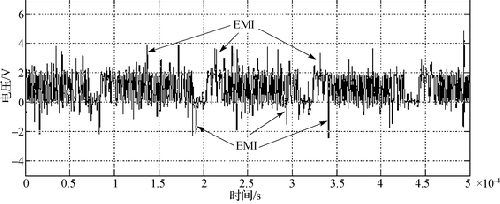
Figure 1 Radiation interference experiment results
The actual bus has also seen the CAN bus failure report [8]: Toyota confirmed in the dealer product report that there were 292 records of lost CAN data in the car recalled by any reason. Glitch is a possible cause of CAN bus error, and its specific induction process needs careful analysis and cannot be taken lightly.
2 CAN bit time and message arbitration principle
The CAN bus divides the bit time into time slices of NBT equal division, called Tq. The CAN bus controller samples the differential levels on the bus by Tq to determine the internal state. When there is no communication on the bus, it is called bus idle, the level difference is 0~0.5 V, and the logic value is "1". The logic value is "0" when the level difference is 0.9 V or more. As can be seen from Fig. 1, there is a "0" burr and there is also a "1" burr. The characteristic of the CAN bus driver is line sum. When "1" and "0" occur simultaneously, the bus level is "0", which is the arbitration function. The first bit to start transmitting in one frame is "0", called SOF, and then the identifier ID of the message. The ID represents the priority of the message. Each node knows the result of arbitration on the bus through bit sampling. If it sends “1†and reads back “0†during normal operation, it means that the sending node fails to send this ID, and needs to wait for the next time. Frame transmission opportunity.
When the bus is idle, a node with a transmission request must first observe whether another node has started to transmit, and cannot send if it has started. It is here that the period starting with a "0" glitch can be misinterpreted as another node has started transmitting SOF, and the glitch blocks the transmission of the node (regardless of how high the priority of the message to be transmitted by the node).
Due to the delay of the transmission cable and the delay τ of the intermediate device (such as optical isolation), the node will not see the SOF of the other node transmitted within the advance amount τ. In the same way, other nodes will see the SOF sent by the node after passing τ. After τ, other nodes will not be allowed to send because they are already sent on the bus. Thus, transmissions within the request time ±τ of the node are considered to be "simultaneous" request transmissions, and they will be arbitrated by ID. It is also inevitable for the transmission of other low priority frames that are later than their τ.
3 CAN bit time synchronization provisions
The bit time of CAN is divided into sync segment (Sync), transmission segment (Tprop), buffer segment 1 (Ph1) and buffer segment 2 (Ph2), and the bit value is sampled between Ph1 and Ph2. When the bit value changes, there will be a transition edge, and only 1/0 is the transition edge for synchronization. The edge of the transition determines the phase difference e, the edge of the transition is negative for Ph in Ph2, 0 for Sync, and positive for Tprop and Ph1. Each node performs synchronization according to e, and the amount of synchronization correction is limited by the type of synchronization. There are two types of synchronization: hard synchronization and resynchronization. The case where the hard synchronization corresponds to the start of the frame, and the case where there is a synchronization edge in the corresponding frame in the resynchronization. For the re-synchronization, the correction amount each time cannot be larger than a pre-settable amount SJW, SJW=min(Ph1, Ph2) called the resynchronization width.
The CAN bus standards for the discussion in this paper are ISO 118981 (2003) [9] and ISO 16845 (2004) [10]. It is these provisions that guarantee that the CAN bus protocol can operate reliably in highly disturbed environments.
According to ISO 118981, Section 10.4.2.2, a node can issue SOF only when the bus is idle, and a "0" at the third bit (IM3) of the service interval is regarded as SOF.
ISO 118981, No. 12.4.2.1 states that hard synchronization is implemented in the interframe space. The interframe interval includes the service interval and the bus idle, and the negative error reporting node for the last transmission also includes the forbidden time. Therefore, the transition edge of IM3 is also used for hard synchronization.
ISO 118981, paragraph 12.4.4.4 stipulates that the purpose of resynchronization is to correct the position of the sampling point. When e is "+", Ph1 is extended, and when e is "-", Ph2 is shortened. The correction amount is e when e is less than or equal to SJW, and is SJW.
Section 7.7.2 of ISO 16845 specifies that the hard-synchronization verification method of the receiving node to the SOF means that the sync segment SYNC is directly synchronized to the 1/0 edge.
ISO 16845 Clause 8.7.2.1 specifies the hard-synchronization verification method for the transmitting node with 1/0 edge before the IM3 bit value sampling point: the test equipment is sent before the Tq plus the measured unit internal processing time before the measured unit IM3 sampling point 0, requires the unit under test to send the highest ID of the ID after the edge of the transition. This means that the sending node is to be hard-synchronized with the 1/0 hopping edge in IM3, the value of 0 is sampled, and the next bit no longer sends SOF but sends the highest bit of the ID.
Section 8.7.3.1 of ISO 16845 specifies the hard synchronization verification method when the transmitting node has a 1/0 edge after the IM3 bit value sampling point: the test equipment is sent after the internal processing time of one of the tested units after the sampling point of the measured unit IM3 0, requires the unit under test to immediately send SOF 1 Tq after the edge of the transition. This means that the sending node is hard-synchronized, but starts sending SOF.
The definitions of the transmitting and receiving nodes are specified in ISO 118981, clauses 4.18 and 4.16. The sending node refers to the node that sends the data frame or the remote frame, and its state is maintained until the arbitration fails to exit or the bus is idle again, otherwise it is the receiving node. Therefore, if the bus encounters a glitch while idle, then everyone is the receiving node.
ISO 7.845, clause 7.7.9 specifies the verification method for the receiving node to filter the glitch when the bus is idle: it is determined that the 0 that is shorter than Tprop+Ph1-1 when the bus is idle is not SOF processed. That is to say, after hard synchronization is not sampled, it is not counted as SOF.
4 glitch causes priority inversion
4.1 Inverted by glitch when the bus is idle
When the bus is idle, the local erroneous 0 glitch is sampled by Tq, and the transmitting node performs hard synchronization according to ISO 16845 7.7.2. Then it is determined according to ISO 16845 7.7.9 whether it is SOF or glitch sent by other nodes. If node H has a request to send ReqH after Tg (as shown in Figure 2), it must also wait for Tprop+Ph1 to determine if the bus is free. If another node L transmits ReqL, its transmission delay to H is τ, and as long as it can be acquired at the sampling point after H's hard synchronization, H no longer has a transmission opportunity. At this time, the time difference between the H and L requests is Tprop+Ph1-τ. If two nodes are close together, τ ≈ 0, then H can't even compete with L that is later than Tprop+Ph1. At the same time, it cannot compete with the transmission of other nodes earlier than τ-1. For the “simultaneous†situation described in Section 1, it is completely incapable of participating in the competition.
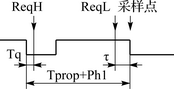
Figure 2 Glitch causes priority inversion when the bus is idle
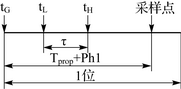
Figure 3 is used to estimate the probability of inversion

Figure 4 Glitch in IM3 causes priority inversion
A preliminary analysis of the probability of a priority inversion is now available. The estimated probability of inversion is shown in Figure 3. tG is the time when the glitch occurs, tH is the high priority message request time, and tL is the low priority message request time. If tH occurs after tG, before the sampling point of the bit, and tL arrives before the sampling point, the request of tH will not be able to obtain the opportunity to participate in the competition. The probability of this is Pa. Pa is related to the bit error rate, and the glitch is picked up with errors. The false positioning time is 1 μs, the burr width is 0.2 μs, and the chance of taking it is 20%, which means that the glitch probability is 5 times of the bit error rate in 1 bit time, considering that there are 0 burrs and 1 burr in the burr. Only 0 glitch will cause false hard synchronization, and then consider that the time period of investigation is Tprop+Ph1, not 1 bit, so conservatively estimate Pa is twice the bit error rate. But Pa is not the probability of inversion due to glitch, but also includes the part of the tL request that is indeed earlier than tH request τ, which is represented by Pb. Pb = (tH - tG - τ) / (tH - tG), and when part of (tH - tG) = τ, part Pb = 0 is subtracted. Therefore, in the worst case, there is no deduction, and the probability of inversion of the priority message is approximately twice the bit error rate.
4.2 Inversion caused by burrs in IM3
Under the resynchronization of the previous frame acknowledgement bit (ACK) "0", the bit time of the two nodes H and L will have a phase difference τ, and the magnitude of τ when L leads will have no effect on the analysis. When nodes H and L both suspend pending messages, they shall start SOF and compete in the latter part of IM3 according to ISO 118981 10.4.2.2. If the H node has a local error, there is a glitch in front of the IM3 bit value sampling point. According to ISO 16845 8.7.2, H will be hard-synchronized, and the bit value sampling point moves so that it can see the SOF sent by L (as shown in the figure). 4), the condition is e>Ph2. Since SOF is read in IM3, H will start sending its highest IDH bit in the next bit. Assume that IDH of H is "01***", IDL of L is "10***", and ID11H of H is transmitted to L via τ, coincides with the SOF portion of L, and continues to ID10L of L. When the e of the glitch meets NBT-(2τ+e)>Ph2, L does not acquire the ID11H of H, so it does not exit. When the bit time is designed, NBT=SYNC+Tprop+Ph1+Ph2, Tprop≥2τ, so the above formula can be satisfied when e<SYNC+Tprop-2τ+Ph1, ie 0<e-Ph2<SYNC+Tprop-2τ+Ph1- Ph2. Generally, Ph1=Ph2, or Ph1=Ph2+1. When the nodes are closer, τ is relatively small, and e has a larger range to satisfy the formula at the same time. The L10's ID10L=0 reaches H after τ, and becomes the synchronization edge in H10's ID10H when e>Ph2, and is sampled by H, and H arbitrates to fail to exit, forming a priority inversion.
The estimation of the probability of such an inversion is more complicated and needs further study.
5 solutions
5.1 Hard synchronization anti-glitch measures when the bus is idle
The receiving node checks for a 1/0 transition edge when the bus is idle and then performs a hard synchronization, and then continues sampling every Tq. If 1 is found before the bit value sampling point, the bus is considered to be in the idle state. If there is a transmission request of the node in between, the next Tq of 1 is found to start the transmission of the node. In this way, the transmission of the node is delayed by the time corresponding to the glitch width, but it is also ensured that no other node has started transmitting before the node is transmitted, so there is no priority inversion.
This method does not address the case where the glitch is wide and the SOF that continues to other nodes arrives. At this time, the node still has priority inversion due to no transmission.
5.2 Hard synchronization anti-burr measures in IM3
A glitch in front of the IM3 sample value causes hard synchronization, and the node continues to sample the bus. When there is "1", the subsequent judgment is more difficult, because the time when the "0" is encountered after the hard synchronization is uncertain, it may be that the SOF sent by another node is received before the original IM3 bit value sampling point, and may also be in the IM3 in-situ value. Received after the sampling point, it may also be a glitch. Therefore, for the sake of simplicity of processing, the own node that suspends the pending frame sends an overload frame. By reporting the overload, the bus returns to the idle state after the overload frame ends, and the synchronization is re-implemented.
This method also does not address the case where the glitch is wide and the SOF that continues to other nodes arrives. At this time, the node still has priority inversion due to no transmission.
6 Summary
The glitch filtering and hard synchronization at the beginning of the frame are requirements for ensuring the two different sides of the communication. In the design of the existing CAN bus protocol, conflicts occur, causing priority inversion in a certain situation. The hazard of priority inversion caused by glitch is related to the type of specific application. Generally speaking, the system design has been designed to prevent burr interference, and the probability of occurrence of glitch is relatively small, and it occurs at a specific position.
In the case of priority inversion, there may be no inversion of the next competition. When doing the worst delivery time analysis [6], the low priority blocking can be doubled for analysis.
But it is also possible that the next inversion will still occur. In the vehicle safety certification analysis, it is necessary to determine the hourly failure rate caused by the inversion, which makes the analysis need to introduce the error rate assumption and requires further work.
This paper proposes an improvement scheme under the condition of full compatibility with CAN bus, but the scheme is only partially effective, and the fundamental improvement may not be fully compatible.
Displayport Cable
In the simplest terms, DisplayPort cables are designed to provide both audio and video signals via a single cable. They are used to connect displays or monitors to a source device such as a PC or laptop and transmit the outputted audio and video data to the display.


displayport to hdmi cable,Mini Displayport to Displayport,Patch Core Cable,Hdmi to Displayport Cable
Pogo Technology International Ltd , https://www.wisesir.net