Li Gong's years of hard work "Programming and Data Structure" and "Programming for AMetal Framework and Interface (I)", after the publication of the book content, set off a learning boom in the electronics industry. Authorized by Professor Zhou Ligong, this public number has serialized the contents of the book "Programming and Data Structure" and is willing to share it.
The second chapter is programming techniques. This article is 2.4.1 incomplete type and 2.4.2 abstract data type.
> > > 2.4.1 Incomplete type
An incomplete type refers to a "type outside the function whose size cannot be determined." The declaration of a structure tag is a typical example of an incomplete type. such as:

At this point, struct _TypeA and struct _TypeB are referenced to each other. Although it is troublesome to declare which side is first, you can avoid the above problem by declaring the structure tag first. such as:

When using a typedef to declare a struct type, such as:

Since a TypeB type tag is declared without knowing its contents, its size cannot be determined. Such a type is called an incomplete type. Because you cannot determine the size, you cannot turn an incomplete type into an array, nor can it be a member of a structure, or be declared as a variable. But if you declare it as a pointer, you can use an incomplete type. TypeB is not an incomplete type when the content of struct _TypeB is subsequently defined.
A structure that does not contain any implementation details is usually declared in the ".h" header file, and then functions defined in conjunction with the specific implementation of the data structure are defined in the ".c" implementation file. Users of the data structure can see the declaration and function prototype, but the implementation is hidden in the ".c" file. Only the information needed to use the data structure is visible to the user, and if too much internal information is visible, the user may use this information to generate dependencies. Once the internal structure changes, the user code may fail. The incomplete type is because the compiler does not see the actual definition in the ".c" file. It can only see the type definition of the _demoB structure, but not the implementation details of the structure.
The following uses an array as an example to describe the use of incomplete types. Although an array can be used to save an element, since the size of the array is fixed, the array does not store its size, and it does not check whether the subscript is out of bounds. The array is usually replaced by a pointer pBuffer pointing to the array and a value count of the number of records array elements. Its implementation is as follows (IA_array.c):

To prevent users from directly accessing members of the structure, the structure is usually hidden from the implementation code (IA_array.c) and then an intArray is declared in the interface (IA_array.h) to process the corresponding data using an incomplete type. Although the object is described in an incomplete type, the information required for the object size is missing. such as:

It tells the compiler that _IntArray is a struct tag, but does not describe the struct of the struct, so the compiler does not have enough information to determine the size of the struct. The intent is that the incomplete type will complete the information elsewhere in the program. . The use of an incomplete type is limited because the compiler does not know its size, so it cannot be declared in the interface with it:

But you can define a pointer type reference in the interface (IA_array.h) to an incomplete type:

Here, just declare its existence, and do nothing else. For the user, only IA_array.h is seen, but nothing is known about the construction or implementation of _IntArray.
When you define an IntArray as a pointer to a struct _IntArray structure type, you can declare a variable of type IntArray* and pass it as a function argument. which is:

Although the IntArray is not yet defined, the size of the pointer is always the same and does not depend on the object it points to. Even if you don't know the details of the structure itself, the compiler also allows you to handle pointers to structures, which explains why C allows this behavior. Although this structure is an incomplete type, the information becomes complete in the implementation code, so the members of the structure depend on the implementation method.
Although arrays and pointers are different, C does not distinguish between them. C provides support for arrays only for the convenience of memory management and pointer arithmetic. The best proof is that the bracket operators are actually interchangeable. When creating an array in the structure, in order to avoid direct access to the data, the interface function interacts with the object. See Listing 2.30 for details.
Listing 2.30 Accessing Array Elements and Size Interfaces (IntArray.h)

To illustrate that these functions form the interface of the IntArray object and prevent the interface between the function name and other objects, the prefix IA_ is used before each function name, and each function has an IntArray* type object as a parameter. This parameter is The object that the function will operate on.
IA_init() initializes the array to an empty element state, and IA_cleanup() releases the memory allocated to the user during the lifetime of the array. The remaining functions control access to the data in the array, IA_setSize() sets the number of elements in the array, and allocates storage for those elements, and IA_getSize() returns the number of elements in the current array. IA_setElem() and IA_getElem() are used to access a single data element, as detailed in Listing 2.31.
Listing 2.31 Accessing an Array Element and Size Interface Implementation (IntArray.c)

Among them, IA_setSize () is used to change the size of the array, first release the original element, then save the new element, and allocate storage space for the new element. Of course, you can also optimize further code, such as reassigning space only when the array size increases. IA_getSize() accesses the element pointed to by the given subscript and lets IntArray check if the subscript is inside the bounds.
It can be seen that the implementation of IntArray is composed of two parts, that is, the data of the object information and the function of the interface of the object. The sample program is shown in Listing 2.32.
Listing 2.32 uses the IntArray.h sample program

> > > 2.4.2 Abstract data types
1. Stack implementation
Assuming you need a character stack and the stack size is fixed, you can use an array to hold the elements in the stack, and then specify a counter to indicate the number of elements in the stack. Its data structure is defined as follows:

Since the caller does not have direct access to the underlying layer, a stack must be created before the element is pushed onto the stack. Its function prototype is:

Since the stack is empty at the beginning, no elements are currently stored in the array elements[0], so you can create an empty stack by setting the subscript of the array to 0. which is:

The form of its call is as follows:

When a new element is pushed into the stack, the element is stored in the space next to the array and incremented. Its function prototype is:

That is, when the value of top is incremented by 1, the new element value value is pushed onto the stack. which is:

When an element is popped, the count is decremented and the top element of the stack is returned. Its function prototype is as follows:

That is, when the value of top is decremented by 1, the top node is deleted and the value of the node is returned. such as:

In addition to these basic operations, it is often necessary to know the number of elements in the stack and whether the stack is empty or full. The prototypes of these functions are:

Obviously, as long as the top value of the stack is returned, it knows how many elements are stored in the stack. When stack->top is 0, the stack is empty. When stack->top is greater than or equal to MAXSIZE, the stack is full.
In fact, when a structure pointer variable stack is defined, (stack->top) becomes a variable, and each of the stacks can be implemented by stack->top and stack->elements[stack->top++] respectively. Member's visit. Obviously the program exposes the internal structure of "array and subscript" and does not prevent the user from directly accessing the members of the structure using the stack pointer variable. such as:
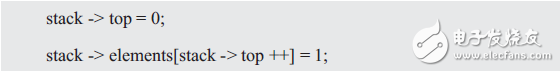
Because of the direct access to top and elements, the user has the potential to corrupt the data in the stack. If its internal implementation changes, the program must be modified accordingly. If the program is very large, the amount of work to be modified is also large, so it is often known that refactoring can improve the program, and it is too unwilling to change the specific implementation due to the heavy workload.
It can be seen that the implementation method of the above stack not only exposes the data structure of the stack, but also has only one stack. What if I need multiple stacks? One way is to write multiple functions with the same name and different functions, so that multiple pieces of code with exactly the same processing will appear. To solve this problem, the abstract method is to hide the data structure in the stack into the implementation code.
2. Create an abstraction
Although standard C provides an indivisible atomic data type like int, char, float, and double, if you need to represent an arbitrarily large integer, it is clear that atomic data types are powerless. At this point, it is imperative to create a new integer type, and this new data type is an abstract data type (ADT).
Designing a Stack-based abstract data type, where should we start? A good way to do this is to describe it in one sentence. This description should be as abstract as possible, try not to involve the internal structure of the data, so simple to anyone can understand it, so you can describe "Stack" is a can be inserted (push) and deleted in the same location (pop The memory of the value, which is the end of the memory, ie the top of the stack. This definition neither states what data is stored in the stack, nor specifies whether to store the data in the form of arrays, structures, or other data, and does not specify how the operations are implemented. These details are left to the implementation.
A detailed description of the stack is as follows:
Type name: Stack
Type attribute: can store ordered data (value)
Type operation: create stack (newStack) and destroy stack (freeStack), add data from the top of the stack (push) and delete data from the top of the stack (pop), determine whether the stack is empty (stackIsEmpty), determine whether the stack is full (stackIsFull) Returns the number of elements in the stack (getStackDepth), reading the elements anywhere in the stack (getStackElement).
That is, you must create a stack before adding elements to the stack. When the memory is no longer used, the stack must be destroyed. The basic operations of the stack are push and pop. The former is equivalent to inserting, and the latter is equivalent to deleting the last inserted element. The pop on the empty stack is considered to be a stack ADT error. On the other hand, running out of space when running push is an implementation error, but not an ADT error.
3. Establish an interface
(1) Isolation changes
In order to prevent users from directly accessing top and elements and destroy the data in the stack, based on past experience, you can use the principle of dependency inversion. The data structure required to implement the implementation of the stack stored in the structure is hidden in the ".c" file, and the interface for processing the data is contained in the ".h" file. The user will not be able to see how the data structure of the stack is at the bottom. Realized.
Although you can think of an array as having a fixed size, the built-in array does not store its size, and it does not check if the subscript is out of bounds. Usually, a pointer to the array data and the value of the record array element number numData storage stack maximum capacity, and the record top element position top is packaged, the stack data structure is hidden in the ".c" file. which is:

For the user, the stack can only be manipulated through the interface in the ".h" file. Although stackCDT is not yet defined at this time, the size of the pointer is always the same and does not depend on the object it points to. Even if you don't know the details of the structure itself, the compiler also allows you to handle pointers to the structure, so you can define a pointer type reference incomplete type, and define stackADT as a pointer to the stackCDT * structure type. such as:

Although this structure is an incomplete type, the information becomes complete in the file that implements the stack, so the members of the structure depend on the implementation of the stack. The variables of the stackADT structure type are defined as follows:

Since a stack1 points to a storage unit, that is, a storage unit represents a stack, how many stacks do you want? such as:
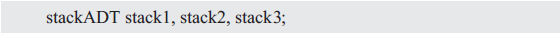
Obviously, stackADT is an abstract data type that represents the general name of all concrete stacks such as stack1, stack2, and stack3. Stack1, stack2, and stack3 point to different stacks. So as long as stack1, stack2, and stack3 are passed as arguments to the corresponding function, you can access the stack corresponding to it. The abstract approach is to add a function layer between the stack's implementation code and the code that uses the stack. such as:

The stackADT type of stack called the function context is usually used as the first argument to the function. This argument is the object that the function will operate on. It represents a pointer to the current object (stack) and is used to request that the object perform some operations on itself. The member variable of the structure is to find the object to which it belongs by using the stack pointer. The reference method is as follows:

Thus, the user interacts with the stack only through interface functions, rather than directly accessing its data.
(2) Operation method
Create stack
Since the user is completely unaware of how the underlying layer is represented, a function for creating a new stackADT must be provided and returned to the user. The function name used to create a new abstract type value begins with new to emphasize dynamic allocation. Its function prototype is as follows:

Precondition: stackADT is defined as a pointer to a structure containing top and numData. Once the maximum capacity is known, the stack can be dynamically determined. Create a stack with the given maximum value MAXSIZE, which allocates space for the stackCDT structure allocation space and the MAXSIZE array. At the same time, top is initialized to 0, and numData is set to the maximum value MAXSIZE.
Postcondition: Return to the stack.
The form of its call is as follows:

Destroy stack
When an interface defines a function that assigns a value to a new abstract type, it usually provides a function for the interface to free the dynamic memory of the stack that the user is no longer using. Its function prototype is as follows:

Precondition: stack points to the stack created earlier;
Postcondition: Release all memory allocated dynamically, that is, release the array of the stack first, and then release the structure of the stack.
The form of its call is as follows:

Add data from the top of the stack (push)
When a user adds a piece of data to the top of the stack, the value is stored in an internal data structure. That is, push is implemented by inserting an element at the top of the container. The function prototype is as follows:

Precondition: stack points to the stack created before, and value is the data to be pushed onto the top of the stack;
Postcondition: If the stack is not full, put the value on the top of the stack, the function returns true, otherwise the stack does not change, the function returns false.
The form of its call is as follows:
Delete data from the top of the stack (popped)
When the user pops up the stack element, the stored value is returned to the user. That is to achieve pop by deleting the elements at the top of the container, the function prototype is as follows:

Precondition: stack points to the stack created earlier, pValue is a pointer to the variable that stores the return value;
Postcondition: If the stack is not empty, copy the value at the top of the stack to *pValue, delete the value at the top of the stack. The function returns true. If the stack is empty before the deletion, the stack does not change, and the function returns false.
The form of its call is as follows:

Determine if the stack is empty
The function prototype for judging whether the stack is empty is as follows:

Precondition: stack points to the stack created earlier;
Postcondition: Returns true if the stack is empty, otherwise returns false.
The form of its call is as follows:

Determine if the stack is full
The function prototype that determines whether the stack is full is as follows:

Precondition: stack points to the stack created earlier;
Postcondition: Returns true if the stack is full, otherwise returns false.
The form of its call is as follows:

Determine the number of elements in the stack
The function prototype for determining the number of elements in the stack is as follows:
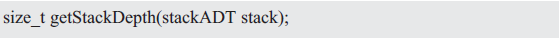
Precondition: stack points to the stack created earlier;
Postcondition: Returns the number of elements in the stack.
The form of its call is as follows:

Read elements anywhere in the stack
The function prototype for reading the elements of the stack stack is as follows:

Precondition: stack points to the stack created earlier, index is the index value, which means that the element in a position in the stack is returned, and pValue is a pointer to the variable that stores the return value;
Postcondition: If the index is greater than top, the function returns false, otherwise the value of the index position is copied to *pValue, and the function returns true.
The form of its call is as follows:
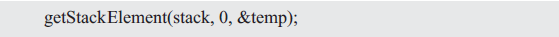
Since the index of the array starts from 0, when index is 0, getStackElemnt(stack, 0, &temp) returns the element at the top of the stack, getStackElemnt(stack, 1, &temp) returns the next element, and so on. .
When encapsulating, only the minimum interface function declaration is placed in the header file, and the internal function must be added with the static keyword. The interface of the abstract stack is detailed in Listing 2.33. The interface reveals the data type of the stack and the various functions that the user needs when operating the stack. These functions implement the basic operations of the abstract stack type.
Listing 2.33 Abstract Stack Interface (stack.h)

These functions together create an interface, each with stackADT as its first argument. When the function interface is declared, the corresponding interface can be implemented.
4. Implement the interface
Since the length of the array is already determined at compile time, it cannot be dynamically adjusted at runtime. However, some applications do not know how much memory space should be allocated at compile time to meet the requirements, so you can use dynamic memory to allocate memory space "at runtime" as needed. As with any interface, implementing the Stack.h interface requires writing a module Stack.c that provides an abstract type of output function and code that represents the details, as detailed in Listing 2.34.
Listing 2.34 Implementation of the abstract stack (Stack.c)

On the surface, the getStackDepth() function looks like only one line of code. Maybe someone would say, why not just use "stack->top;" instead of the function? If the user uses top in the program, the program will depend on the concrete structure represented by stackADT, and the benefit of using this function is to provide an isolation layer between the user and the implementation. Since maintaining code is an important step in the software engineering lifecycle, be prepared to make changes as much as possible.
Of course, the above program still can't create two stacks with different data types. The most common method is to use void * as the data type, so you can push and pop any pointer of any type. It will not be described in detail here and will be left to the reader to implement. However, the biggest disadvantage of using void * as a data type is that error detection cannot be performed. Stacks that store void * data allow various types of pointers to coexist, and therefore cannot detect errors caused by pushing the wrong pointer type.
5. Using the interface
In fact, the person using the stack does not care how the stack is implemented. Even if you want to change the internal implementation of the stack, you don't need to make any changes to the program that uses the stack. The sample program that pushes the integer onto the stack and then prints out is shown in Listing 2.35.
Listing 2.35 Sample program using the stack interface

In summary, the interface of the Stack stack is divided into two parts, one is to describe how to represent data, and the other is to describe the function that implements the ADT operation, so the method of storing data must be provided first. Design a structure, define the abstract data type stackADT of the stack in the ".h" interface, and define the stack type specific stackXT in the ".c" implementation. Second, you must provide functions (methods) that manage the data, hiding their underlying implementations through function prototypes. As long as they retain their interfaces, their implementation can be changed for any abstraction. In fact, when an abstract data type stackADT is introduced, the dependency inversion principle is used to completely separate the data needed to implement the stack in the structure from the interface that handles the data, because stackADT does not expose its details, and the user relies on it. Abstraction in satcADT, not details.
Obviously, abstract data types can construct new structures using existing atomic data types, combining new operations with operations that have already been implemented. For ADT, the user program does not access any data values ​​other than those mentioned in the interface. The representation of the data and the functions that implement the operations are all within the implementation of the interface and are completely separate from the user. The abstract interface hides irrelevant details. The user can't see the implementation of the method through the interface, focus on the essential features, and free the programmer from the details of how the program is implemented. For any abstraction, as long as the interface remains the same, we can change its implementation as needed.
SMP series Rack-mounted DC Power Supplies are economical, MOSFETs-based, high switching speed, high power density DC power supplies with output power covering 300W ~ 6KW, and maximum voltage up to 800VDC.
Compared with IGBT-based DC switching power supplies, MOSFET-based switching power supplies have a higher switching frequency, making this series Rack DC power supplies can use smaller semiconductor devices and LC filter units while ensuring low ripple, high precision, and fast response characteristics of the Power Supplies DC output. Which gives more space to use a smaller chassis size at the same output power, resulting the high-power density feature of this series Rack Mounted DC power supplies.


Rack-mounted DC Power Supplies, Rack Mounted DC Power Supplies, DC Rack Power Supplies, Rack Switching Power Supplies, Rack Mount DC Power Supplies
Yangzhou IdealTek Electronics Co., Ltd. , https://www.idealtekpower.com