Deepmind’s achievements on Alphago have brought the reinforcement learning method into the mainstream learning field of artificial intelligence. [Learning from scratch] also seems to be a way to abandon human prior experience, acquire new skills, and defeat humans in various games. "Secrets". Andrey Kurenkov from Stanford questioned this foundation of reinforcement learning. In this article, he started from the basic principles of reinforcement learning and recent achievements, affirmed its results, and also pointed out the fundamental limitations of reinforcement learning. The Big Data Digest compiles the essence of this article.
Have you ever played board games?
Assuming you can't play, or even never touched it.
Now your friend invites you to play against him and is willing to tell you how to play.
Your friend is very patient. He taught you the steps of chess by hand, but he never tells you the meaning of every move he took, only telling you the result of winning or losing the game at the end.
The game begins. Because of "inexperience", you keep losing. But after many "failure experiences", you gradually discovered some patterns.
A few weeks have passed, and you can finally win the battle after thousands of actual games.
Quite stupid, right? Why don't you directly ask why and how to play this chess?
However, this method of learning to play chess is actually the epitome of most reinforcement learning methods today.
What is reinforcement learning?
Reinforcement learning is one of the basic sub-fields of artificial intelligence. In the framework of reinforcement learning, the agent interacts with the environment to learn what actions to take to maximize the long-term reward in a given environment, as in the above In the fable of the board game, you learn by interacting with the board.
In the typical model of reinforcement learning, the agent only knows which actions can be done, and does not know any other information. It only relies on the interaction with the environment and the reward of each action to learn.
The lack of prior knowledge means that the role must be learned from scratch. We call this method of learning from scratch "Pure RL".
Pure reinforcement learning is widely used in games such as Backgammon and Go, as well as in robotics and other fields.
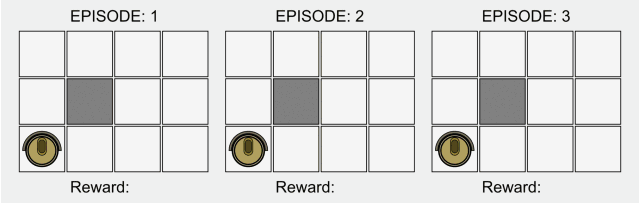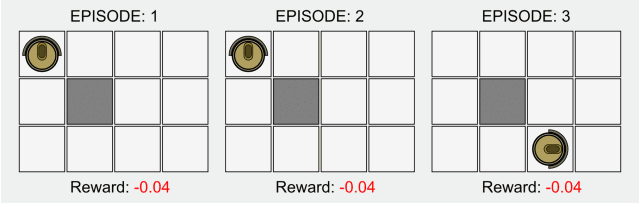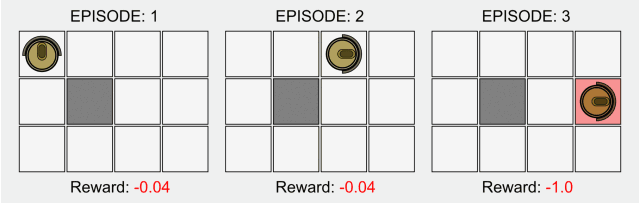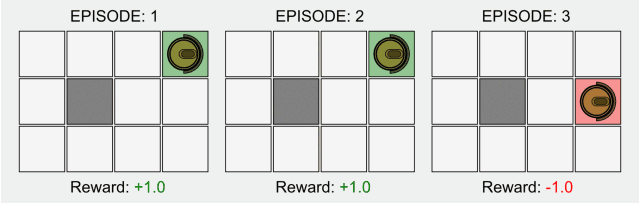
In traditional reinforcement learning, there is only a non-zero reward in the final state. Research in this field has recently received attention again because of deep learning, but its basic model has not been improved.
After all, this kind of learning method from scratch can be traced back to the initial creation period of the field of reinforcement learning, and it was also coded in the original basic formula.
So the fundamental question is: if pure reinforcement learning is meaningless, is it reasonable to design an AI model based on pure reinforcement learning?
If it sounds so absurd for humans to learn new board games through pure reinforcement learning, should we consider whether this is a framework that is inherently flawed, and how can AI characters learn effectively through this framework? ? Does it really make sense to learn without relying on any previous experience or guidance, just relying on reward signals?
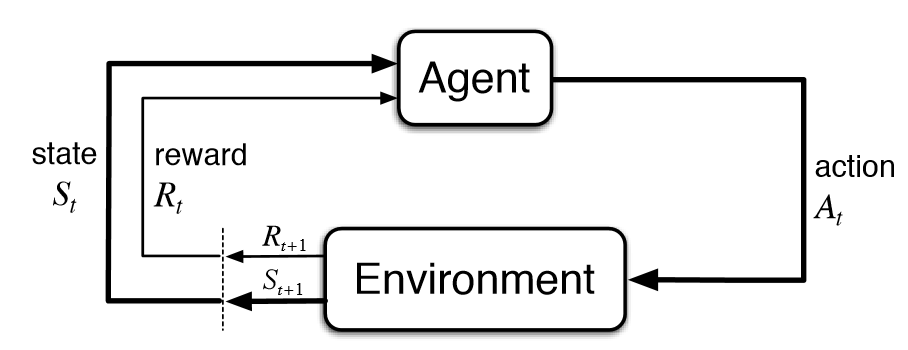
The basic formula of reinforcement learning
Does pure reinforcement learning really make sense?
Regarding this issue, reinforcement learning experts have different opinions:
Have! Pure reinforcement learning certainly makes sense. AI agents are not real humans, so they don’t need to learn like us. Besides, pure reinforcement learning can solve many complex problems.
No! From a definition point of view, AI research includes allowing machines to do things that only humans can currently do, so it is reasonable to compare with human intelligence. As for the problems that pure reinforcement learning can solve now, people always ignore one point: those problems are not as complicated as they seem.
Since the industry cannot reach a consensus, let us speak with facts.
Based on pure reinforcement learning, industry players represented by DeepMind have achieved many "cool" achievements:
1) DQN (Deep Q-Learning)-DeepMind's well-known research project combines deep learning and pure reinforcement learning, and adds some other innovations to solve many complex problems that could not be solved before. This project five years ago greatly increased people's research interest in reinforcement learning.
It is no exaggeration to say that DQN rekindled the researchers' enthusiasm for reinforcement learning on its own. Although DQN has only a few simple innovations, these innovations are critical to the practicality of deep reinforcement learning.
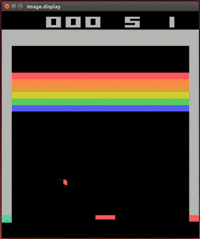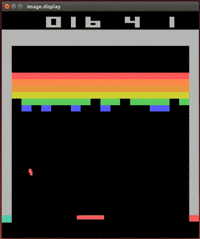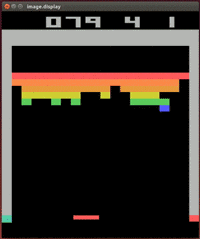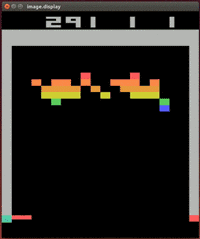
Although this game looks very simple now, only learning through pixel input, it was unimaginable to play this game ten years ago.
2) AlphaGo Zero and AlphaZero-a reinforcement learning model purely used to defeat humans in Go, Chess and Japanese Shogi
Let’s start with a popular science: AlphaGo Zero is the latest upgraded version of AlphaGo developed by Google’s DeepMinwd project. Unlike the original AlphaGo that combines supervised learning and reinforcement learning, AlphaGo Zero relies solely on reinforcement learning and self-play for algorithm learning.
Therefore, although the model also uses a pre-provided algorithm rule, namely chess game rules and self-playing to carry out more reliable and continuous iterative updates, AlphaGo Zero follows the overall methodology of pure reinforcement learning: the algorithm starts from scratch, Iterate through the reward signal feedback of the learning result.
Because it does not learn the rules of the game directly from humans, AlphaGo Zero is therefore considered by many to be a more disruptive algorithm than AlphaGo. Then came AlphaZero: As a more general algorithm, it can learn not only how to play Go, but also chess and Japanese shogi.
This is the first time in history that a single algorithm is used to crack chess and Go algorithms. Moreover, it does not make any special customization to any game rules like the deep blue computer or AlphaGo in the past.
There is no doubt that AlphaGo Zero and AlphaZero are milestone cases in the history of reinforcement learning.

Historic moment-Li Shidong lost to AlphaGo
3) OpenAI's Dota robot-an AI agent driven by a deep reinforcement learning algorithm that can defeat humans in the popular complex multiplayer battle game Dota2. OpenAI's record of defeating professional players in a 1v1 game with limited changes in 2017 is amazing enough. Recently, it beat a whole team of human players in a much more complicated 5v5 game.
This algorithm is also in the same line as AlphaGo Zero, because it does not require any human knowledge and trains the algorithm purely through self-play. In the video below, OpenAI explains its achievements brilliantly.
Undoubtedly, in this highly complex game based on teamwork, the good results achieved by the algorithm are far superior to previous wins in Atari video games and Go.
More importantly, this evolution was done without any major algorithmic progress.
This achievement is attributed to the amazing amount of calculations, mature reinforcement learning algorithms, and deep learning. In the artificial intelligence industry, the general consensus is that the victory of Dota robots is an amazing achievement and the next in a series of important milestones in reinforcement learning:
Yes, pure reinforcement learning algorithms have achieved a lot.
But when we think about it carefully, we will find that these achievements are actually "not too bad."
The limitations of pure reinforcement learning
Let's start with DQN and review the limitations of pure reinforcement learning in the cases just mentioned.
It can reach the level of Superman in many Atari games, but generally speaking, it can only do well in reflection-based games. In this game, you don't actually need reasoning and memory.
Even today, 5 years later, there is no pure reinforcement learning algorithm that can crack inference and memory games; on the contrary, the methods that do a good job in this regard either use instructions or use demonstrations, and these are also used in board games. It works.
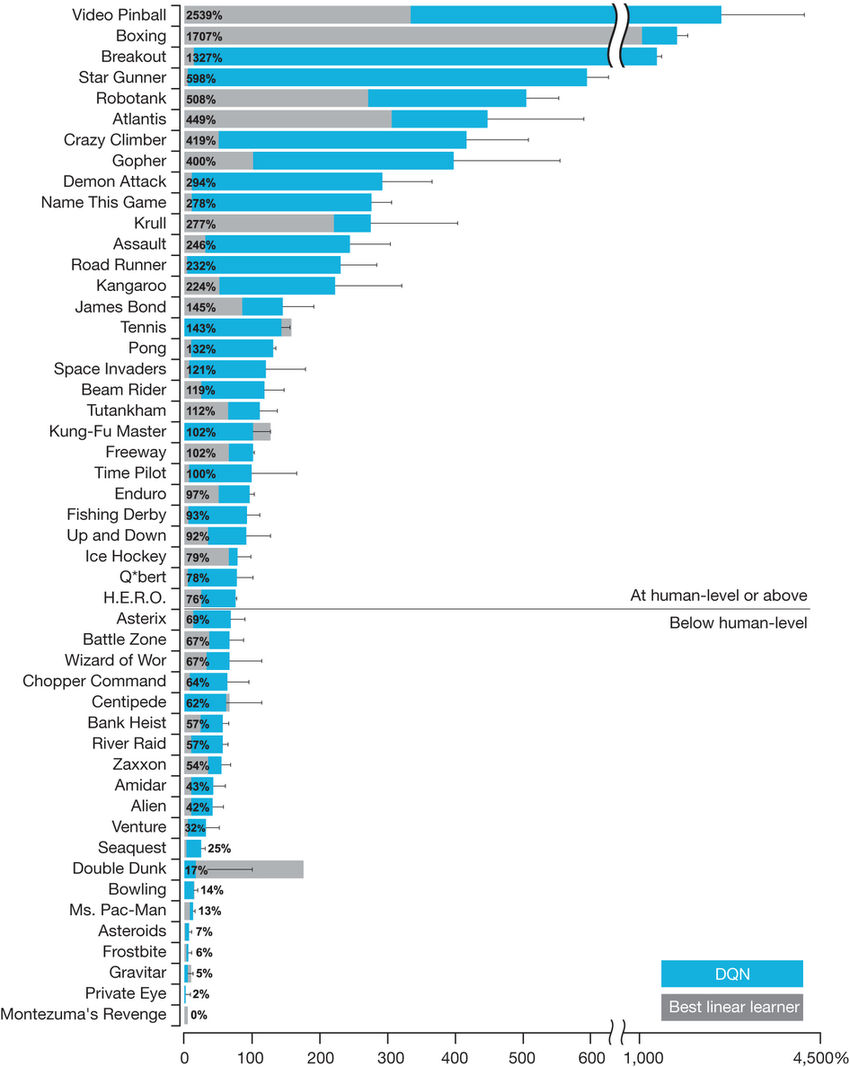
Although DQN performs well in games such as Breakout, it still cannot complete relatively simple games like Montezuma's Revenge.
Even in games where DQN performs well, it still requires a lot of time and experience to learn compared to humans.
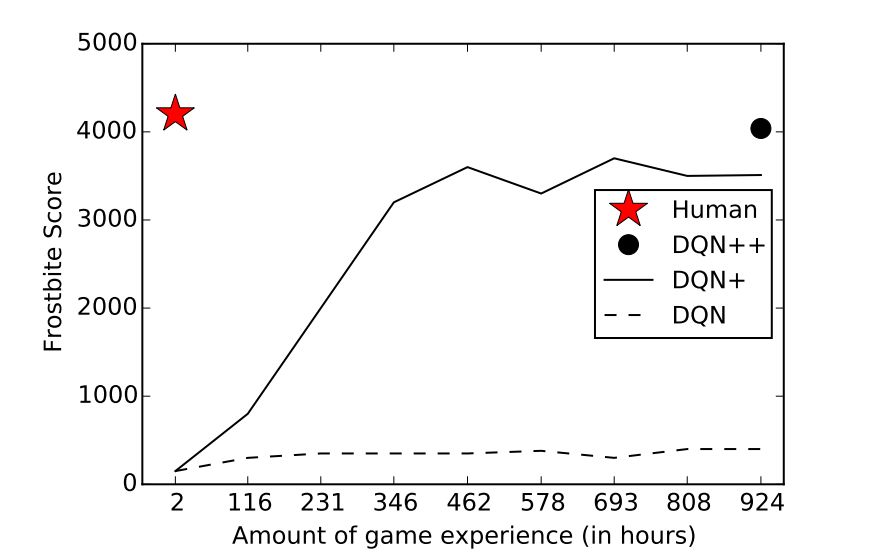
The same limitation also exists in AlphaGo Zero and AlphaZero.
That is to say, each of its properties makes the learning task easy: it is deterministic, discrete, static, fully observable, fully known, single-agent, suitable for the situation, Cheap, easy to simulate, easy to score...
But under this premise, the only challenge for the game of Go is: it has a huge branching factor.
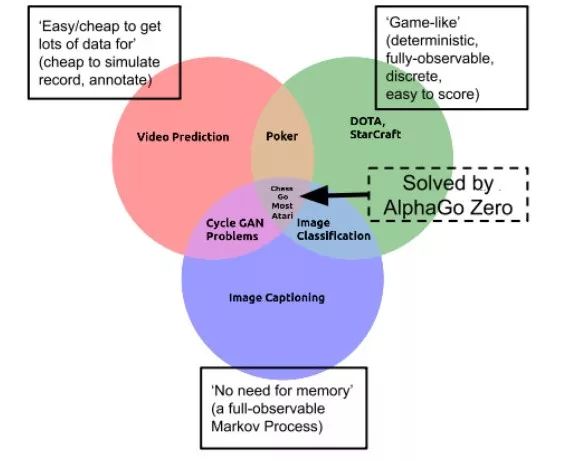
So, although Go may be the most difficult problem in easy mode, it is still easy mode. And most researchers recognize that most problems in the real world are much more complicated than simple games like Go.
Despite many outstanding achievements, all variants of AlphaGo are still similar in nature to "Deep Blue": it is an expensive system designed for years and invested millions of dollars, but purely for fun An abstract board game-nothing else.
Now it's Dota.
Yes, this is a much more complicated game than Go. It lacks many features that make the game simple: it is not discrete, static, fully observable, single-agent or suitable for situations-this is A very challenging problem.
However, it is still an easy-to-simulate game, controlled through a beautiful API-it completely eliminates the need for perception or motion control. Therefore, it is still simple compared to the real complexity we face in solving problems in the real world every day.
It is still like AlphaGo and requires large-scale investment. In order to get an algorithm, many engineers use ridiculously long time to solve this problem. This even requires thousands of years of game training and uses up to 256 GPUs and 128,000 CPU cores.
Therefore, it is incorrect to believe that pure reinforcement learning is very powerful just because of these results of reinforcement learning.
What we have to consider is that in the field of reinforcement learning, pure reinforcement learning may only be the first method used, but maybe, it may not be the best?
The fundamental flaw of pure reinforcement learning-starting from scratch
Is there a better way for AI agents to learn Go or Dota?
The meaning of the name "AlphaGo Zero" means that the model learns Go from scratch. Let us recall the example from the beginning. Since trying to learn board games from scratch without any explanation is absurd, why does AI have to learn from scratch?
Let us imagine, for humans, how would you start learning Go?
First, you will read the rules, learn some high-level strategies, recall how you played similar games in the past, and then get some advice from the masters.
Therefore, the limitations of AlphaGo and OpenAI Dota robots learning from scratch have caused them to rely on many orders of magnitude game instructions and use more primitive and unmatched computing power compared with human learning.
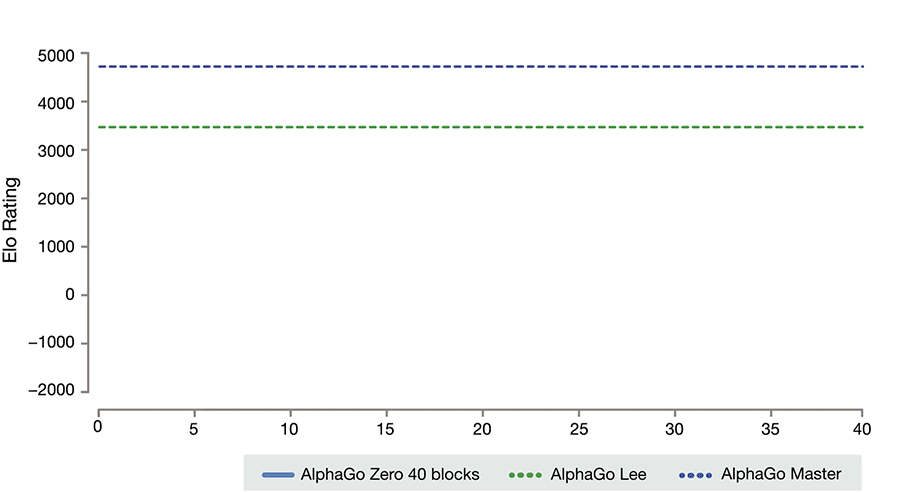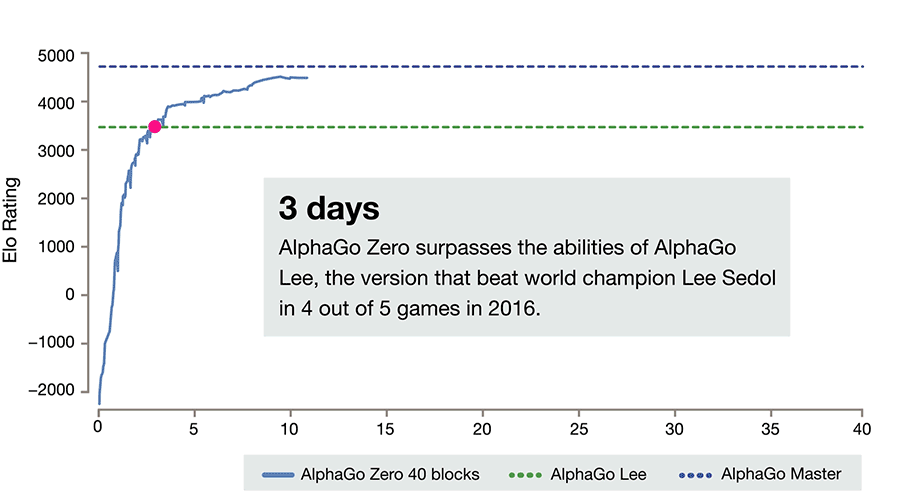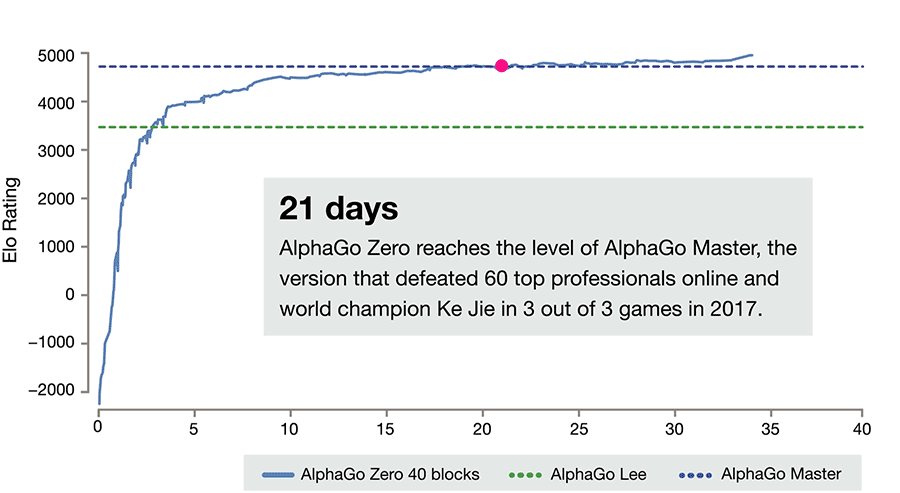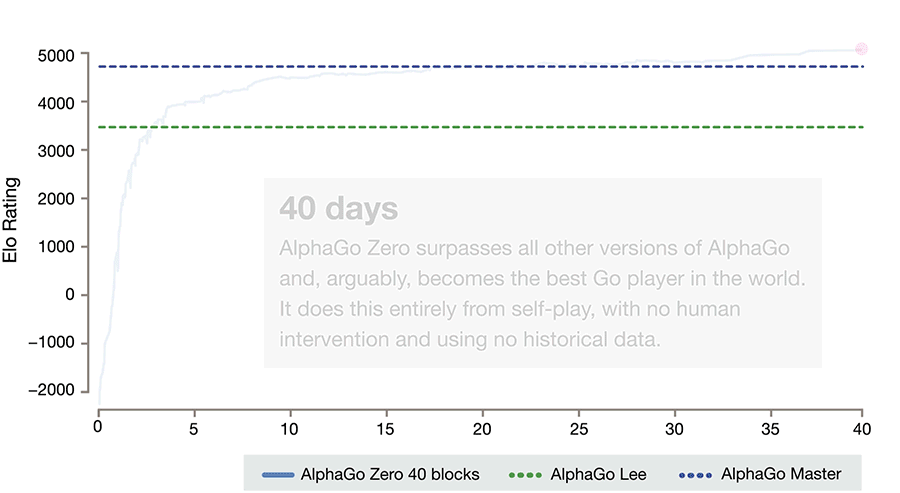
The progress of AlphaGo Zero. Please note that to reach an ELO score of 0, it takes a whole day and thousands of games (and even the weakest person can easily do it).
To be fair, pure reinforcement learning can be reasonably used for “narrow†tasks such as continuous control, or recent complex games such as Dota or StarCraft.
However, with the success of deep learning, the AI ​​research community is now trying to solve increasingly complex tasks that must face the real-world complexity. It is these complexities that we may need something beyond pure reinforcement learning.
So, let us continue to discuss our correction problem: Is pure reinforcement learning, and the idea of ​​learning from scratch in general, the right way to accomplish complex tasks?
Should we still insist on pure reinforcement learning?
At first glance, the answer to this question may be: yes. Why do you say that?
Learning from scratch means that it does not have any preconceived subjective factors. In this way, the learned artificial intelligence will be better than us, just like AlphaGo Zero. After all, if humans have direct errors, wouldn't they limit the learning capabilities of machines?
With the success of deep learning methods, this view has become mainstream. Although the amount of data for training models is amazing, we still only give a small amount of prior knowledge.
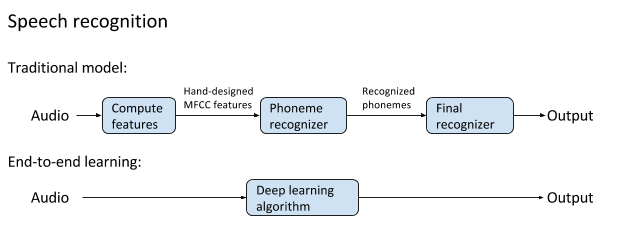
Examples of previous non-traditional speech recognition and end-to-end deep learning methods, the latter has better performance and has become the basis of modern speech recognition.
However, let us re-examine this question: Will combining human prior knowledge necessarily limit the learning ability of machines?
the answer is negative. In other words, under the framework of deep learning (that is, starting from data only), we can give certain instructions to the task at hand without limiting the learning ability of the machine.
At present, there have been many studies in this direction, and it is believed that such technology can also be applied to practical examples soon.
For example, for algorithms like AlphaGo Zero, we don't have to learn from scratch. Instead, we add human knowledge guidance without restricting their learning ability.
Even if you think this direction is unreliable and insist on learning from zero, is pure reinforcement learning our best choice?
In the past, the answer is unquestionable; in the field of gradientless optimization, pure reinforcement learning is the most complete theory and the most reliable method.
However, many recent articles have questioned this assertion because they have discovered relatively simple methods (and generally less appreciated), methods based on evolutionary strategies seem to perform as well as pure reinforcement learning in some typical tasks:
"Simple random search provides a competitive approach to reinforcement learning"
"Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning"
The Big Data Digest WeChat public account backstage replied "defects" to download these two papers.

Ben Recht is the leader of theoretical and practical research on optimization algorithms. He concluded:
We found that random search is better than reinforcement learning in simple linear problems, such as policy gradients. However, when we encounter more difficult problems, will random search crash? not at all.
Therefore, it cannot be said that reinforcement learning is the best way to learn from zero.
Going back to the problem of human learning from zero, do humans learn a new complex skill without any prior knowledge (such as assembling a piece of furniture or driving a car)? It’s not like that, right?
Perhaps for some very basic problems (such as what babies need to learn), we can start from scratch and use pure reinforcement learning, but for many important problems in the AI ​​field, starting from scratch has no special advantage: we must be clear , What we want AI to learn, and must provide demonstrations and guidance in this regard.
In fact, it is widely believed that learning from scratch is the main reason why reinforcement learning models are restricted:
The current AI is "data dependent"-in most cases, AI requires massive amounts of data to play its role. This is very disadvantageous for pure reinforcement learning techniques. Recall that AlphaGo Zero requires millions of games to reach the level of 0 ELO score, and humans can reach this level in very little time. Obviously, learning from scratch is the least efficient learning method;
The current AI is opaque-in most cases, we only have high-level intuition for learning AI algorithms. For many AI problems, we hope that the algorithm is predictable and interpretable. But a giant neural network that learns everything from scratch has the worst interpretability and predictability. It can only give some low-level reward signals or an environmental model.
At present, AI is narrow-in many cases, AI models can only perform very well in specific areas and are very unstable. The model of learning from scratch limits the ability of artificial intelligence to learn.
The current AI is fragile-AI models can only generalize massive amounts of data as invisible inputs, but the results are very unstable. Therefore, we can only know what we want the AI ​​agent to learn.
If you are a person, you should be able to explain the task and provide some suggestions before you start learning. The same applies to AI.
A new rule from the Drug Enforcement Administration (DEA) threatens to upend the American hemp industry, and could even result in criminal prosecutions for manufacturers of CBD and delta-8 THC products.
The DEA says the [interim final rule," issued Aug. 20, is simply a matter of adjusting its own regulations to account for changes to the Controlled Substances Act that were mandated by the 2018 Farm Bill (or Agricultural Improvement Act) that legalized hemp and CBD production. The new rule [merely conforms DEA`s regulations to the statutory amendments to the CSA that have already taken effect," says the agency. The new rule doesn`t break any ground, according to the DEA.
But many experts on cannabis and hemp law say the DEA rule creates a potential pathway the law enforcement agency could use to prosecute hemp processors and producers of CBD (cannabidiol) and delta-8 THC (or Δ8THC) products. There are two issues: partially processed CBD, and [synthetically derived" delta-8 THC.
Cbd Pod System Oem,Cbd Vape Pod Oem,Best Cbd Pod System,Cbd Pod System
Shenzhen MASON VAP Technology Co., Ltd. , https://www.e-cigarettefactory.com