* The revised code for this article has been uploaded to the Apollo project on the GitHub website.
{ 1 }
Thread pool technology
1 definition of a thread pool
Thread pool is a multi-threaded form. It starts a specified number of background worker threads and adds multiple tasks to be executed to the task queue. Then, the tasks in the queue are handed over to idle worker threads one by one (as shown in the following figure). .
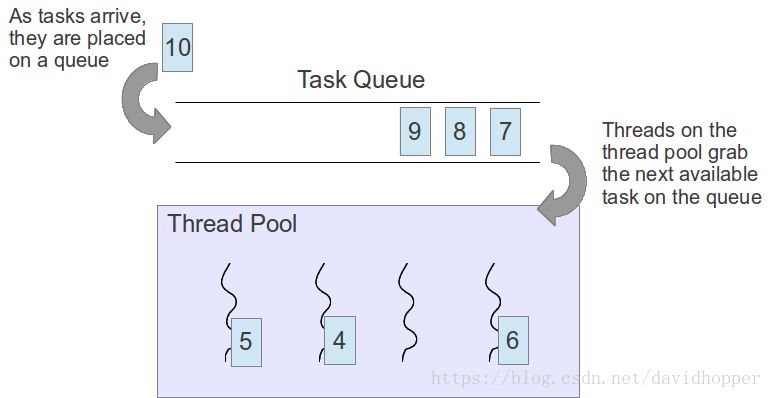
2 reasons for using the thread pool
Creating/destroying threads along with operating system resource overhead and creating/destroying threads too frequently can greatly affect processing efficiency. If the creation thread consumes time T1, the execution task consumes time T2, and the destruction thread consumes time T3. If T1+T3>T2, it is not worthwhile to open a thread to execute a task, and the thread pool cache thread can be used already. There are idle threads to perform new tasks, effectively avoiding the system overhead caused by T1+T3.
There are too many thread concurrency, preempting system resources and causing blocking. We know that threads will share system resources. If there are too many threads that execute at the same time, it may lead to insufficient system resources and result in the operation of Caton or even suspended animation. Using the thread pool can effectively control the maximum number of concurrent threads, effectively avoiding the above problems.
Make some simple management of threads. For example: delay execution, timing loop execution and other strategies, the use of thread pool is relatively easy to implement.
How to use thread pool in 3C++
The C++ standard library does not provide a thread pool. If you want to use it, you need to write its own thread pool class. There are several implementations of thread pool classes in GitHub, and the Apollo project also references one of these implementations [https://github.com/vit-vit/CTPL].
{ 2 }
Apollo thread pool class source code analysis
The Apollo thread pool file is located in [your_apollo_root_dir]/modules/common/util/ctpl_stl.h and contains the task queue class Queue and the thread pool class ThreadPool, where the Queue is located in the namespace apollo::common::util::detail and the ThreadPool is named Space apollo::common::util.
1 Task Queue Queue
Task queue class Queue based on the C++ standard library queue class std::queue To achieve, only the push, pop and empty three functions are locked.
| Template Class Queue { public: bool push(T const &value) { // use std::lock_guard more efficient std::unique_lock Lock(mutex_); q_.push(value); return true; } // deletes the retrieved element, do not use for non integral types bool pop(T &v) { // NOLINT // is more efficient with std::lock_guard Std::unique_lock Lock(mutex_); if (q_.empty()) { return false; } v = q_.front(); q_.pop(); return true; } bool empty() { // use std::lock_guard more efficiently High std::unique_lock Lock(mutex_); return q_.empty(); } private: std::queue Q_; std::mutex mutex_;}; |
According to the introduction of this blog [https://blog.csdn.net/tgxallen/article/details/73522233], we can use std::lock_guard and std::unique_lock to provide RAII (Resource Acquisition Is Initialization, See the page's [https://blog.csdn.net/doc_sgl/article/details/43028009] style lock operation, where std::lock_guard has a lower system overhead and std::unique_lock is more flexible. Unlock). For our task queue class Queue, the flexibility provided by std::unique_lock is not needed, so it is more appropriate to use std::lock_guard. In addition, I also added a push function that accepts a right-value reference to facilitate the use of the ThreadPool below. The modified class is as follows:
| Class Queue { public: bool push(const T &value) { std::lock_guard Lock(mutex_); q_.push(value); return true; } // Add a push function that accepts an rvalue reference bool push(T &&value) { std::lock_guard Lock(mutex_); q_.emplace(std::move(value)); return true; } // deletes the retrieved element, do not use for non integral type bool pop(T &v) { // NOLINT std::lock_guard Lock(mutex_); if (q_.empty()) { return false; } v = q_.front(); q_.pop(); return true; } bool empty() { std::lock_guard Lock(mutex_); return q_.empty(); } private: std::queue Q_; std::mutex mutex_;}; |
2 thread pool class ThreadPool
The main function of the thread pool class ThreadPool is to create n_threads background worker threads and wrap the task function f into std::function The form is stored in the task queue q_. According to the idle status of the current worker thread, a task function is extracted and executed from the task queue q_. Note that the copy constructor ThreadPool(const ThreadPool &), the move constructor ThreadPool(ThreadPool &&), the copy operator ThreadPool &operator=(const ThreadPool &), and the move operator ThreadPool &operator=(ThreadPool &&) are all set to private, indicating that the use is prohibited These functions. In fact, the completion of the C++11 standard can be disabled by adding the function =delet; after the function declaration, the source code gives this implementation in a commented manner.
The following analysis of several more important member functions in this class.
2.2.1 Push function
The function of the Push function is to wrap the task function f into std::function The form is stored in the task queue q_. There are two versions of the Push function. One allows the task function f to have the variable parameter Rest &&... rest. One does not allow the task function f to have extra parameters. The internal code of the function body is much the same. The following analysis is performed with the version with variable parameters. code show as below:
| Template Auto Push(F &&f, Rest &&... rest) -> std::future { // std::placeholders::_1 indicates that the first parameter accepted by the asynchronous task object that is bound through the std::bind function is the free parameter auto pck = std::make_shared >( std::bind(std::forward (f), std::placeholders::_1, std::forward (rest)...)); // It's best to use std::make_shared to create a smart pointer object, and don't worry about freeing pointer memory // auto _f = std::make_shared >([pck](int id) { (*pck)(id); }); auto _f = new std::function ([pck](int id) { (*pck)(id); }); q_.push(_f); // Do not add a lock here, otherwise it will cause a deadlock std::unique_lock Lock(mutex_); cv_.notify_one(); return pck->get_future();} |
The return value of the Push function is a std::future object, and the data type stored in the std::future object is determined by the return value type of the (f(0, rest...) function, decltype(f(0, rest.. The purpose of .)) is to get the return value type of the (f(0, rest...) function. std::future provides an access mechanism for the result of the asynchronous operation, literally, it means the future, I think this The name is very appropriate, because the result of an asynchronous operation is not immediately available, but only at some time in the future. About std::future, this blog [https://blog.csdn.net/yockie/article/details/ 50595958] It's very good, everyone can learn from it.
Because the statement of the task function f is all sorts of, some without parameters, some accept one parameter, some accept two parameters... Therefore, it cannot be directly stored in the task queue q_, so first use the std::bind function Wrap it as an asynchronous operation task std::packaged_task The object pck (receives an integer argument, return value type is the return type of the (f(0, rest...) function), and then uses the Lambda expression to wrap the pck as a std::function Objects, which can be stored in the task queue q_. Here, the original author directly uses the new operator to create a raw pointer _f, and I still need to think of ways to release the pointer memory. I think it is not very appropriate. Creating smart pointers using std::make_shared can automatically manage memory and save time, but use std:: Shared_ptr > The smart pointer cannot be stored in the task queue using the Queue:: push (const T & value) version, for which I added a version of Queue:: push (T && value) that accepts the right-valued reference parameter in the Queue class. This version can be successfully stored in the smart pointer.
Next, use the condition variable std::condition_variable object cv_.notify_one () function to notify each thread task queue has changed, let the idle thread quickly pull the new task execution from the task queue; finally returned by pck->get_future () A std::future object, so that the caller can retrieve the function's return value after execution.
I have read a lot of C++ multi-threaded books ("C++ Concurrency in Action" is more classic), generally do not lock cv_.notify_one (); because doing so in addition to reducing efficiency, it is easy to cause deadlock, so Need to remove the lock operation, the specific reason see this page [https://stackoverflow.com/questions/17101922/do-i-have-to-acquire-lock-before-calling-condition-variable-notify-one] and other A web page [http://en.cppreference.com/w/cpp/thread/condition_variable/notify_one].
The following is the revised version:
| Template Auto Push(F &&f, Rest &&... rest) -> std::future { auto pck = std::make_shared >( std::bind(std::forward (f), std::placeholders::_1, std::forward (rest)...)); auto _f = std::make_shared >([pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f) ); cv_.notify_one(); return pck->get_future();} |
2.2.2 Pop function
The function of the Pop function is to take out and return a task from the task queue q_, the code is as follows:
| Std::function Pop() { std::function *_f = nullptr; q_.pop(_f); // If the task queue q_ stores smart pointers, it is not necessary to use this trick to free up memory. Std::unique_ptr > func( _f); // at return, delete the function even if an exception occurred std::function f; if (_f) f = *_f; return f;} |
First, the raw pointer _f of a task function object is taken from the task queue q_, if it is not empty, it is assigned to std::function f and return. This function uses a little trick that creates a smart pointer std::unique_ptr > func(_f), when the object's scope is exceeded, the delete operator is called in its destructor to free memory. If the task queue q_ stores smart pointers, it is not necessary to use this trick to free up memory.
The following is the revised version:
| Std::shared_ptr > Pop() { std::shared_ptr > f; q_.pop(f); return f;} |
2.2.3 Stop function
Stop function to stop the work of the thread pool, if you do not allow to wait, then directly stop the currently executing worker thread, and empty the task queue; if waiting is allowed, then wait for the currently executing worker thread to complete, the code is as follows:
| Void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { * (flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if (is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command To finish } { // Do not add a lock here, otherwise it will cause a deadlock std::unique_lock Lock(mutex_); cv_.notify_all(); // stop all waiting threads } for (int i = 0; i < static_cast (threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if There were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // therefore delete them here ClearQueue(); threads_.clear(); flags_.clear();} |
Why are the boolean variables is_stop_, is_done_, flags_[i] in the function not locked? This is because they are all atomic type std::atomic The so-called atomic type is a CPU instruction that can complete the variable or value type operation. C++ standard guarantees std::atomic Type variables can use a single CPU instruction to perform value or write operations in any architecture operating system. Others are std::atomic The type, although declaring it as an atomic type, cannot use a single CPU instruction to perform value or write operations in some architecture operating systems. In summary, std::atomic Variables of type can be unlocked without multithreading.
According to the analysis in Section 2.2.1, the locking operation of cv_.notify_all(); should be removed.
The modified code is as follows:
| Void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { * (flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if (is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command To finish } cv_.notify_all(); // stop all waiting threads for (int i = 0; i < static_cast (threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if There were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // therefore delete them here ClearQueue(); threads_.clear(); flags_.clear();} |
2.2.4 ClearQueue function
ClearQueue function is to empty the task queue q_, the code is as follows:
| Void ClearQueue() { std::function *_f; // empty the queue while (q_.pop(_f)) { delete _f; }} |
Use the while loop to pop up the task function pointer _f one by one from the task queue q_, because _f is created with the new operator, so delete it with the delete operator to free memory. If a smart pointer is stored in the task queue q_, it is not necessary to manually delete the object to release the memory.
The following is the version using smart pointers:
| Void ClearQueue() { std::shared_ptr > f; // empty the queue while (q_.pop(f)) { // do nothing } } |
2.2.5 Resize Function
The role of the Resize function is to change the number of worker threads in the thread pool. The code is as follows:
| Void Resize(const int n_threads) { if (!is_stop_ && !is_done_) { int old_n_threads = static_cast (threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) {flags_[i] = std::make_shared >(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; -i) { *(flags_[i]) = true ; // this thread will finish threads_[i]->detach(); } { // stop the detached threads that were waiting // don't lock here, otherwise it will cause a deadlock std::unique_lock Lock(mutex_); cv_.notify_all(); } // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not Originals flags_.resize(n_threads); } }} |
If both variables is_stop_, is_done_ are not true, indicating that the thread pool is still in use, the number of worker threads in the thread pool can be changed, otherwise it is not necessary to change the number of worker threads for a deactivated thread pool. If the number of new threads n_threads is larger than the current number of working threads old_n_threads, the sizes of the thread array threads_ and the thread flag arrays_ are modified to the new number, and the foreach loops are used to call the SetThread(i) function to recreate the worker threads one by one; The number of new threads n_threads is less than the number of current work threads old_n_threads, then the task that old_n_threads - n_threads threads are executing is completed first, and then the sizes of the worker thread arrays_ and the thread flag array_ are modified to the new number.
According to the analysis in section 2.2.1, the locking operation of cv_.notify_all() should be removed. For details, see the web page.
Note: The Resize function is dangerous. It should be called as little as possible. If it must be called, it should be called inside the thread that created the thread pool, not in other threads.
The modified code is as follows:
| Void Resize(const int n_threads) { if (!is_stop_ && !is_done_) { int old_n_threads = static_cast (threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) {flags_[i] = std::make_shared >(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; -i) { *(flags_[i]) = true ; // this thread will finish threads_[i]->detach(); } // stop the detached threads that were waiting cv_.notify_all(); // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not originals flags_.resize(n_threads); } }} |
2.2.6 SetThread function
The function of the SetThread function to re-create the worker thread with the specified sequence number i, the code is as follows:
| Void SetThread(int i) { std::shared_ptr > flag( flags_[i]); // a copy of the shared ptr to the flag auto f = [this, i, flag /* a copy of the shared ptr to the flag */]() { std::atomic &_flag = *flag; std::function *_f; bool is_pop_ = q_.pop(_f); while (true) { while (is_pop_) { // if there is anything in the queue // If the smart queue is stored in task queue q_, you don't have to use this Kinds of flowers tricked to release memory. Std::unique_ptr > func( _f); // at return, delete the function even if an exception // occurred // The execution task function (*_f)(i); if (_flag) { // the thread is wanted to stop, return even If the queue is not // empty yet return; } else {is_pop_ = q_.pop(_f); } } // the queue is empty here, wait for the next command // This must use std::unique_lock because The condition variable cv_ needs to be unlocked during the waiting period. Std::unique_lock Lock(mutex_); ++n_waiting_; // Wait for the new task from the task queue. cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || Is_done_ || _flag; }); --n_waiting_; if (!is_pop_) { // if the queue is empty and is_done_ == true or *flag // then return return; } } }; threads_[i].reset( New std::thread(f)); // compiler may not support std::make_unique() } |
The above code looks complicated, in fact there are only three statements, the first is std::shared_ptr > flag(flags_[i]);, which uses flags_[i] to initialize the flag variable flag; the second one looks long, actually creating a Lambda expression variable f; the third is threads_[i]. Reset(new std::thread(f)); uses the Lambda expression variable f as the task function of the worker thread to create a worker thread of sequence number i.
So when does the Lambda expression variable f start? When the return value of the task queue q_.pop(_f) is true, it indicates that a new task has been fetched from the task queue q_, and then (*_f)(i) is executed; if the current task queue has no task, then use:
| Cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || is_done_ || _flag;}); |
Waiting for the arrival of a new task, the current worker thread is dormant until the new task arrives.
This function also uses a little trick that creates a smart pointer std::unique_ptr > func(_f), when the object's scope is exceeded, the delete operator is called in its destructor to free memory. If the task queue q_ stores smart pointers, it is not necessary to use this trick to free up memory.
2.2.7 Modified ThreadPool Class Code
For completeness, here's the modified ThreadPool class code.
| Class ThreadPool { public: ThreadPool() { Init(); } explicit ThreadPool(int n_threads) { Init(); Resize(n_threads); } // the destructor waits for all the functions in the queue to be finished ~ThreadPool() { Stop(true); } // get the number of running threads in the pool int size() { return static_cast (threads_.size()); } // number of idle threads int NumIdle() { return n_waiting_; } std::thread &GetThread(const int i) { return *(threads_[i]); } // change the number Of threads in the pool // should be called from one thread, otherwise be careful to not interleave, // also with stop() // n_threads must be >= 0 void Resize(const int n_threads) { if (!is_stop_ && ! Is_done_) { int old_n_threads = static_cast (threads_.size()); if (old_n_threads <= n_threads) { // if the number of threads is increased threads_.resize(n_threads); flags_.resize(n_threads); for (int i = old_n_threads; i < n_threads; ++i) {flags_[i] = std::make_shared >(false); SetThread(i); } } else { // the number of threads is decreased for (int i = old_n_threads - 1; i >= n_threads; -i) { *(flags_[i]) = true ; // this thread will finish threads_[i]->detach(); } // stop the detached threads that were waiting cv_.notify_all(); // safe to delete because the threads are detached threads_.resize(n_threads); // safe to delete because the threads // have copies of shared_ptr of the // flags, not originals flags_.resize(n_threads); } } } // empty empty queue ClearQueue() { std::shared_ptr > f; // empty the queue while (q_.pop(f)) { // do nothing } } // pops a functional wrapper to the original function std::shared_ptr > Pop() { std::shared_ptr > f; q_.pop(f); return f; } // wait for all computing threads to finish and stop all threads // may be called asynchronously to not pause the calling thread while waiting // if is_wait == true, all The functions in the queue are run, otherwise the // queue is cleared without running the functions void Stop(bool is_wait = false) { if (!is_wait) { if (is_stop_) { return; } is_stop_ = true; for (int i = 0, n = size(); i < n; ++i) { *(flags_[i]) = true; // command the threads to stop } ClearQueue(); // empty the queue } else { if ( Is_done_ || is_stop_) return; is_done_ = true; // give the waiting threads a command to finish } cv_.notify_all(); // stop all await threads for (int i = 0; i < static_cast (threads_.size()); ++i) { // wait for the computing threads to finish if (threads_[i]->joinable()) { threads_[i]->join(); } } // if There were no threads in the pool but some functions in the queue, the // functions are not deleted by the threads // but delete them here ClearQueue(); threads_.clear(); flags_.clear(); } template Auto Push(F &&f, Rest &&... rest) -> std::future { auto pck = std::make_shared >( std::bind(std::forward (f), std::placeholders::_1, std::forward (rest)...)); auto _f = std::make_shared >([pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f) Cv_.notify_one(); return pck->get_future(); } // run the user's function that excepts argument int - id of the running // thread. returned value is templatized // operator returns std::future, where The user can get the result and rethrow // the catched exceptins template Auto Push(F &&f) -> std::future { auto pck = std::make_shared >( std::forward (f)); auto _f = std::make_shared >([pck](int id) { (*pck)(id); }); // It is not necessary to lock q_ because it is locked in the Queue class. q_.push(std::move(_f) Cv_.notify_one(); return pck->get_future(); } private: // deleted ThreadPool(const ThreadPool &); // = delete; ThreadPool(ThreadPool &&); // = delete; ThreadPool &operator=(const ThreadPool &); // = delete; ThreadPool &operator=(ThreadPool &&); // = delete; void SetThread(int i) { std::shared_ptr > flag( flags_[i]); // a copy of the shared ptr to the flag auto f = [this, i, flag /* a copy of the shared ptr to the flag */]() { std::atomic &_flag = *flag; std::shared_ptr > _f; bool is_pop_ = q_.pop(_f); while (true) { while (is_pop_) { // if there is anything in the queue (*_f)(i); if (_flag) { // the thread is Wanted to stop, return even if the queue is not // empty yet return; } else { is_pop_ = q_.pop(_f); } } // the queue is empty here, wait for the next command { std::unique_lock Lock(mutex_); ++n_waiting_; cv_.wait(lock, [this, &_f, &is_pop_, &_flag]() { is_pop_ = q_.pop(_f); return is_pop_ || is_done_ || _flag; }); N_waiting_; if (!is_pop_) { // if the queue is empty and is_done_ == true or *flag // then return return; } } } }; threads_[i].reset( new std::thread(f)) ; // compiler may not support std::make_unique() } void Init() { is_stop_ = false; is_done_ = false; n_waiting_ = 0; } std::vector > threads_; std::vector >> flags_; detail::Queue >> q_; std::atomic Is_done_; std::atomic Is_stop_; std::atomic N_waiting_; // how many threads are waiting for std::mutex mutex_; std::condition_variable cv_;}; |
2.2.8 Added Unit Test Code
To verify the correctness of the modified code, add the following unit test code. The first parameter to be tested, filter_duplicates_str, accepts the first parameter as an integer ID value. I used it as a placeholder in the test code, but it was not actually used. It was followed by four C-style strings. The task is to remove duplicate words from the four strings and sort the deduplicated results in ascending alphabetical order. The result is returned as std::string; the second filter_duplicates function to be tested only accepts an integer ID value parameter. , I just used it as a placeholder in the test code. It is not actually used. The task of this function is to remove duplicate words in a string of fixed strings and sort the deduplicated results in ascending alphabetical order. The result is std. ::string returns. Because the C++ compiler cannot derive the correct version of an overloaded function, the second function to be tested does not use overloaded functions. Both functions to be tested are executed 1000 times using the thread pool. Finally, the consistency between the returned result and the expected result is checked.
| #include "modules/common/util/ctpl_stl.h"#include #include #include #include #include #include #include "gtest/gtest.h"namespace apollo {namespace common {namespace util {namespace {// ...// Attention: don't use overloaded functions, otherwise the compiler can't // deduce the correct edition.std ::string filter_duplicates_str(int id, const char* str1, const char* str2, const char* str3, const char* str4) { // id is unused. std::stringstream ss_in; ss_in << str1 << " " < < str2 << " " << str3 << " " << str4; std::set String_set; std::istream_iterator Beg(ss_in); std::istream_iterator End; std::copy(beg, end, std::inserter(string_set, string_set.end())); std::stringstream ss_out; std::copy(std::begin(string_set), std::end( String_set), std::ostream_iterator (ss_out, " ")); return ss_out.str();}std::string filter_duplicates(int id) { // id is unused. std::stringstream ss_in; ss_in << "aabbbc foo foo bar foobar foobar hello world Hello hello world"; std::set String_set; std::istream_iterator Beg(ss_in); std::istream_iterator End; std::copy(beg, end, std::inserter(string_set, string_set.end())); std::stringstream ss_out; std::copy(std::begin(string_set), std::end( String_set), std::ostream_iterator (ss_out, " ")); return ss_out.str();}} // namespaceTEST(ThreadPool, filter_duplicates) { const unsigned int hardware_threads = std::thread::hardware_concurrency(); const unsigned int threads = std::min (hardware_threads != 0 ? hardware_threads : 2, 50U); ThreadPool p(threads); std::vector > futures1, futures2; for (int i = 0; i < 1000; ++i) {futures1.push_back(std::move(p.Push( filter_duplicates_str, "thread pthread", "pthread thread good news", "today Is a good day", "she is a six years old girl"))); futures2.push_back(std::move(p.Push(filter_duplicates))); } for (int i = 0; i < 1000; + +i) { std::string result1 = futures1[i].get(); std::string result2 = futures2[i].get(); EXPECT_STREQ( result1.c_str(), "a day girl good is news old Pthread she six thread today years "); EXPECT_STREQ(result2.c_str(), "ab bar c foo foobar hello world "); }}} // namespace util} // namespace common} // namespace apollo |
{3}
Analysis of the use of thread pool by Apollo Planning module
The Apollo Planning module uses the PlanningThreadPool class to complete the wrapper call to the thread pool ThreadPool. The PlanningThreadPool class is located in the header file [your_apollo_root_dir]/modules/planning/common/planning_thread_pool.h and the corresponding implementation file [your_apollo_root_dir]/modules/planning/common/planning_thread_pool.cc in the namespace apollo::planning.
1PlanningThreadPool class
The PlanningThreadPool class declaration is as follows:
| Class PlanningThreadPool { public: void Init(); void Stop() { if (thread_pool_) { thread_pool_->Stop(true); } } template Void Push(F &&f, Rest &&... rest) { func_.push_back(std::move(thread_pool_->Push(f, rest...))); } template Void Push(F &&f) { func_.push_back(std::move(thread_pool_->Push(f))); } void Synchronize(); private: std::unique_ptr Thread_pool_; bool is_initialized = false; // The func_ is used here is very inappropriate because it is a std::future object, // instead of a std::function object, it is necessary to modify it to futures_. Std::vector > func_; DECLARE_SINGLETON(PlanningThreadPool);}; |
PlanningThreadPool defines a single instance class with the DECLARE_SINGLETON macro, so you cannot create objects of this class directly on the stack and heap, but only use PlanningThreadPool::instance() to get the unique instance of the class. The member variable func_ in this class is very misleading, in fact it is a dynamic array that holds multiple std::future objects, instead of saving the std::function object, which means that it holds the asynchronous function The return value object, not the asynchronous function object itself, so it is necessary to modify it here to futures_.
Use of 2PlanningThreadPool class
The steps for using the PlanningThreadPool class in the Planning module are as follows:
3.2.1 Initialize the thread pool
Add the following statement in the Planning::Init() function (located in [your_apollo_root_dir]/modules/planning/planning.cc) to complete the initialization of the PlanningThreadPool class object:
| // initialize planning thread pool PlanningThreadPool::instance()->Init(); |
3.2.2 Concurrency processing using the thread pool
Calling the thread pool in a suitable location to perform concurrent processing of a function is generally in a loop body. Note: Tasks that need to be processed concurrently cannot have successive dependencies on each other because when using the thread pool to execute concurrent tasks, they do not know which task will be executed first and which task will be executed later.
The Planning module currently uses thread pools in the following places:
ReferenceLineInfo::AddObstacles function ReferenceLineInfo::AddObstacles function (in [your_apollo_root_dir]/modules/planning/common/reference_line_info.cc) Use PlanningThreadPool::instance()->Push to add thread pool tasks in the for loop to increase the current The obstacle information, use PlanningThreadPool::instance()->Synchronize() to wait for the completion of the thread pool task.
| Bool ReferenceLineInfo::AddObstacles(const std::vector & obstacles) {if (FLAGS_use_multi_thread_to_add_obstacles) {std::vector Ret(obstacles.size(), 0);for (size_t i = 0; i < obstacles.size(); ++i) { const auto* obstacle = obstacles.at(i); PlanningThreadPool::instance()- >Push(std::bind( &ReferenceLineInfo::AddObstacleHelper, this, obstacle, &(ret[i])));}PlanningThreadPool::instance()->Synchronize();if (std::find(ret.begin (), ret.end(), 0) != ret.end()) { return false;}} else {// ...}return true;} |
DPRoadGraph::GenerateMinCostPath function DPRoadGraph::GenerateMinCostPath function (located in [your_apollo_root_dir]/modules/planning/tasks/dp_poly_path/dp_road_graph.cc) Using PlanningThreadPool in the for loop of multiple horizontal sampling points at each waypoint ::instance()->Push Adds a thread pool task to calculate the minimum cost of the current waypoint. Use PlanningThreadPool::instance()->Synchronize() to wait for the thread pool task to complete.
| Bool DPRoadGraph::GenerateMinCostPath( const std::vector &obstacles, std::vector *min_cost_path) { // ... for (std::size_t level = 1; level < path_waypoints.size(); ++level) { const auto &prev_dp_nodes = graph_nodes.back(); const auto &level_points = path_waypoints[level] ; graph_nodes.emplace_back(); for (size_t i = 0; i < level_points.size(); ++i) { const auto &cur_point = level_points[i]; graph_nodes.back().emplace_back(cur_point, nullptr); auto &cur_node = graph_nodes.back().back(); if (FLAGS_enable_multi_thread_in_dp_poly_path) { PlanningThreadPool::instance()->Push(std::bind( &DPRoadGraph::UpdateNode, this, std::ref(prev_dp_nodes), level, total_level , &trajectory_cost, &(front), &(cur_node))); } else { UpdateNode(prev_dp_nodes, level, total_level, &trajectory_cost, &front, &cur_node); } } if (FLAGS_enable_multi_thread_in_dp_poly_path) { PlanningThreadPool::instance()->Synchronize( ); } } // ...} |
DpStGraph::CalculateTotalCost函数 DpStGraph::CalculateTotalCost函数(ä½äºŽ[your_apollo_root_dir]/modules/planning/tasks/dp_st_speed/dp_st_graph.ccä¸ï¼‰åœ¨for循环内使用PlanningThreadPool::instance()->Pushæ·»åŠ çº¿ç¨‹æ± ä»»åŠ¡ï¼Œå¯¹äºŽæ—¶é—´é‡‡æ ·å€¼c上的ä¸åŒè·ç¦»é‡‡æ ·å€¼r: next_lowest_row<=r<=next_highest_row计算抵达节点(c, r)的最å°æ€»ä»£ä»·ï¼Œä½¿ç”¨PlanningThreadPool::instance()->Synchronize()ç‰å¾…çº¿ç¨‹æ± ä»»åŠ¡å…¨éƒ¨å®Œæˆã€‚
| Status DpStGraph::CalculateTotalCost() { // col and row are for STGraph // t corresponding to col // s corresponding to row uint32_t next_highest_row = 0; uint32_t next_lowest_row = 0; for (size_t c = 0; c < cost_table_.size(); ++c) { int highest_row = 0; int lowest_row = cost_table_.back().size() - 1; for (uint32_t r = next_lowest_row; r <= next_highest_row; ++r) { if (FLAGS_enable_multi_thread_in_dp_st_graph) { PlanningThreadPool::instance()->Push( std::bind(&DpStGraph::CalculateCostAt, this, c, r)); } else { CalculateCostAt(c, r); } } if (FLAGS_enable_multi_thread_in_dp_st_graph) { PlanningThreadPool::instance()->Synchronize(); } for (uint32_t r = next_lowest_row; r <= next_highest_row; ++r) { const auto& cost_cr = cost_table_[c][r]; if (cost_cr.total_cost() < std::numeric_limits ::infinity()) { int h_r = 0; int l_r = 0; GetRowRange(cost_cr, &h_r, &l_r); highest_row = std::max(highest_row, h_r); lowest_row = std::min(lowest_row, l_r); } } next_highest_row = highest_row; next_lowest_row = lowest_row; } return Status::OK();} |
3.2.3 销æ¯çº¿ç¨‹æ±
在Planning::Stop()函数(ä½äºŽ[your_apollo_root_dir]/modules/planning/planning.cc)ä¸æ·»åŠ 如下è¯å¥ä»¥ä¾¿é”€æ¯çº¿ç¨‹æ± :
| 1 | PlanningThreadPool::instance()->Stop(); |
自Apolloå¹³å°å¼€æ”¾å·²æ¥ï¼Œæˆ‘们收到了大é‡å¼€å‘者的咨询和å馈,越æ¥è¶Šå¤šå¼€å‘者基于Apollo擦出了更多的ç«èŠ±ï¼Œå¹¶æ„¿æ„将自己的æˆæžœè´¡çŒ®å‡ºæ¥ï¼Œè¿™å……分体现了Apollo『贡献越多,获得越多ã€çš„å¼€æºç²¾ç¥žã€‚为æ¤æˆ‘们开设了『开å‘者说ã€æ¿å—,希望开å‘者们能够踊跃投稿,更好地为广大自动驾驶开å‘者è¥é€ 一个共享交æµçš„å¹³å°ï¼
Buzzer Wire Harness
Buzzer with Speaker for Alarm System Appliance, This is used for audio, video, radio, automotive, motocycle, bus, bike, truck .
1) Professional wire harness manufacturer for home appliance, Electronic, industrial control, medical and so on. We have good business with some top 500 future company, like Lenovo, Huawei, HP, Eaton, etc.
2) Our wire complies with UL/CE certification; all comply with above ROHS 2.0. Support customer especially request like no red phosphorus. Our company has got ISO2000 certificates.
3) We accept OEM/ODM design, welcome any customized cable too, whenever you have 500pcs or 100K pcs demand, we will reply you quickly and quote you best prices if we can support.
4) Strict quality control, Passed TS Quality control system, All the products are 100% test before delivery.
Wiring Harness Kit,Electronic Buzzer Automatic Wire Harness,Buzzer Automatic Wire Harness,Buzzer Wire Harness
Dongguan YAC Electric Co,. LTD. , https://www.yacentercns.com