Natural language processing is an important direction in the field of computer science and artificial intelligence. It studies various theories and methods that enable effective communication between humans and computers in natural language. Natural language processing is a science that integrates linguistics, computer science, and mathematics. Therefore, research in this field will involve natural language, the language that people use every day, so it is closely related to the study of linguistics, but there are important differences. Natural language processing is not a general study of natural language, but rather a computer system that can effectively implement natural language communication, especially a software system therein. It is therefore part of computer science. Natural Language Processing (NLP) is a field of computer science, artificial intelligence, and linguistics that focus on the interaction between computers and human (natural) languages.
Natural language processing detailsLanguage is the essential characteristic of human beings to distinguish other animals. Of all living things, only humans have language skills. Many kinds of human intelligence are closely related to language. The logical thinking of human beings takes the form of language, and most of human knowledge is recorded and passed down in the form of language and characters. Therefore, it is also an important and even core part of artificial intelligence.
Communicating with computers in natural language is something that people have been pursuing for a long time. Because it has obvious practical significance, but also has important theoretical significance: people can use the computer in their most accustomed language, without spending a lot of time and energy to learn various computer languages ​​that are not very natural and habitual; It can also be used to further understand human language and intelligence mechanisms.
Realizing natural language communication between human and computer means that the computer can understand the meaning of natural language texts as well as natural language texts to express a given intention, thought and so on. The former is called natural language understanding, and the latter is called natural language generation. Therefore, natural language processing generally includes two parts: natural language understanding and natural language generation. Historically, there have been more studies on natural language understanding, but less on natural language generation. But this situation has changed.
Whether it is to achieve natural language understanding or natural language generation, it is far less simple than people originally thought, but it is very difficult. From the current theoretical and technical status quo, the universal, high-quality natural language processing system is still a long-term goal, but for certain applications, practical systems with considerable natural language processing capabilities have emerged, and some have been commercialized. And even began to industrialize. Typical examples are: natural language interfaces for multilingual databases and expert systems, various machine translation systems, full-text information retrieval systems, automated summarization systems, and more.
Natural language processing, which is to achieve natural language communication between human and computer, or to achieve natural language understanding and natural language generation is very difficult. The root cause of the difficulties is the wide variety of ambiguities or ambiguities that exist widely in natural language texts and at all levels of dialogue.
A Chinese text is a string of Chinese characters (including punctuation, etc.). Words can form words, words can form words, words can form sentences, and then some sentences form segments, sections, chapters, and articles. There is ambiguity and polysemy in the various levels mentioned above: words (characters), words, phrases, sentences, paragraphs, ... or in the next level of transition, that is, a string of the same form, In different scenes or different contexts, it can be understood as different word strings, phrase strings, etc., and have different meanings. In general, most of them can be resolved according to the corresponding context and the rules of the scene. In other words, there is no ambiguity in general. This is why we do not feel natural language ambiguity and can communicate correctly in natural language. But on the one hand, we also see that in order to dispel ambiguity, it requires a great deal of knowledge and reasoning. How to collect and organize this knowledge more completely; how to find the right form and store them in the computer system; and how to use them effectively to eliminate ambiguity is a very difficult and very difficult task. . This is not something that a few people can accomplish in a short period of time. It still needs long-term, systematic work.
The above said that a Chinese text or a Chinese character (including punctuation, etc.) string may have multiple meanings. It is the main difficulty and obstacle in the understanding of natural language. Conversely, an identical or similar meaning can also be represented by multiple Chinese texts or multiple Chinese character strings.
Therefore, there is a many-to-many relationship between the form (string) of natural language and its meaning. In fact, this is also the charm of natural language. But from the perspective of computer processing, we must eliminate ambiguity, and some people think that it is the central problem in natural language understanding, that is, to convert the natural language input with potential ambiguity into some unambiguous internal representation of the computer.
The widespread existence of ambiguity makes the elimination of them require a lot of knowledge and reasoning, which brings great difficulties to linguistic-based and knowledge-based methods. Therefore, these methods are the mainstream of natural language processing research for decades. In terms of theory and method, many achievements have been made, but in terms of system development that can deal with large-scale real texts, the results are not significant. Most of the systems developed are small, research-based demonstration systems.
There are two problems in the current problems: on the one hand, the grammar to date is limited to the analysis of an isolated sentence, the context and the context of the conversation have no systematic research on the constraints and influences of this sentence, so the analysis of ambiguity, word ellipsis, pronouns There are no clear rules to follow the different meanings of the same sentence on different occasions or by different people. It is necessary to strengthen the study of pragmatics to solve it step by step. On the other hand, people understand that a sentence is not just grammar, but also uses a lot of relevant knowledge, including life knowledge and expertise, which cannot be stored in the computer. Therefore, a written understanding system can only be established within a limited range of vocabulary, sentence patterns and specific topics; it is possible to expand the scope appropriately after the storage and operation speed of the computer is greatly increased.
The above problems become the main problem of natural language understanding in machine translation application. This is one of the reasons why the translation quality of machine translation systems is still far from ideal goals. The quality of translation is the key to the success of machine translation system. Professor Zhou Haizhong, a Chinese mathematician and linguist, once pointed out in the classic paper "Fifty Years of Machine Translation": To improve the quality of machine translation, the first thing to solve is the problem of language itself rather than the problem of programming; To be a machine translation system, it is certainly impossible to improve the quality of machine translation; in addition, in the case that humans have not yet understood how the brain performs fuzzy recognition and logical judgment of language, the degree to which machine translation wants to achieve "letter, dad, elegance" is not possible.
An example of common methods for natural language processingNatural language processing, or text mining and data mining, has been a hot topic of research recently. Many people think about data mining, or natural language processing, there is an inexplicable sense of distance. In fact, when you walk in, you will find its beauty, its beauty in solving real problems in the real life, the beauty of mathematics combined with it, and its natural integration with statistics. Language is just an implementation tool. The real difficulty is the understanding of the model and the construction of the model.
The following is an example of a common method of natural language (JAVA implementation, similar to C#)1, the basic use of the entity

2, batch read the files under the directory

3, read a single file

4 file preprocessing and return as a string result

5 Specify to save the file
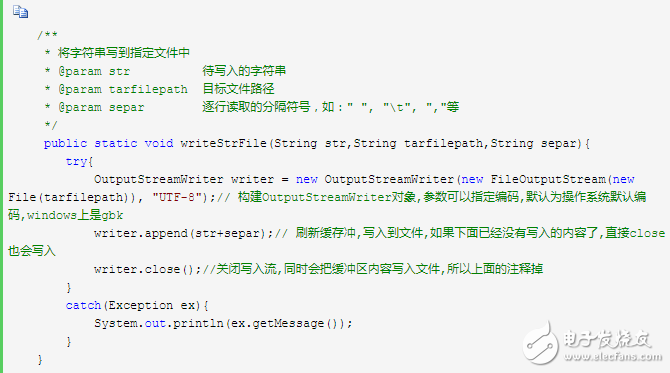
6 word frequency sorting (common in both English and Chinese)
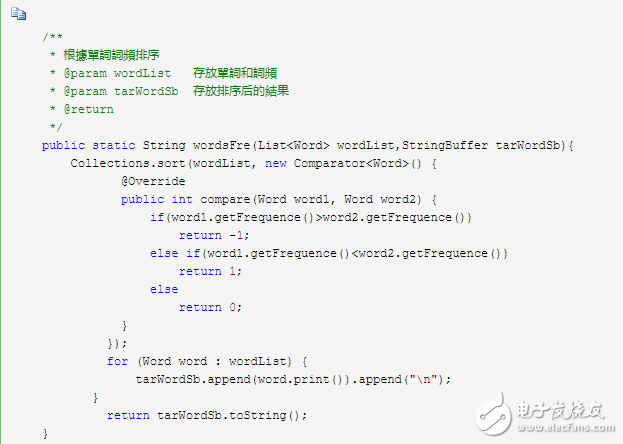
7 arranged according to characters

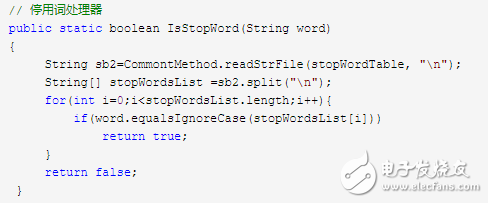
8 How to judge the stop word processing?
The project was initially improved due to actual needs. Basic natural language processing methods and procedures are included, such as word frequency statistics, stop word processing, word statistics, and basic operations of files, combined with mathematical models or statistical models can do complex natural language or text processing. For example, the naive Bayes classification, first understand the Bayesian classification model, is actually the understanding and derivation of the Bayesian formula. After that, combined with the project word frequency statistics file operation, data cleaning, Chinese word segmentation, stop word processing will be made. For example, ontology construction is also required to implement data cleaning, word frequency statistics, result emission probability and transition probability, and text annotation.
As for the improvement of the algorithm, the translation part can be improved, and a lexicon-based search, including part of speech, word meaning, word mark and the like. The other is the word segmentation of English phrases, which is solved by English word segmentation. In terms of porting, you can use the C# language to develop on the form, and finally package the application software.
The Kassel AC Servo Motor has a wide range of speed regulation, has super overload capability and stall capability, and runs smoothly, with low noise, low temperature rise, and beautiful appearance. The new model has lower heat and faster response. It can be matched with the corresponding Servo Drive device to form a servo system to create a first-class motion control scheme.
Ac Servo Motor,Ac Servo,Ac Servo Motor In Control System,Ac And Dc Servo Motor
Kassel Machinery (zhejiang) Co., Ltd. , https://www.kasselservo.com